Evaluating Dialogue Generation Systems via Response Selection
Shiki Sato, Reina Akama, Hiroki Ouchi, Jun Suzuki, Kentaro Inui
Dialogue and Interactive Systems Short Paper
Session 1B: Jul 6
(06:00-07:00 GMT)

Session 2B: Jul 6
(09:00-10:00 GMT)
Abstract:
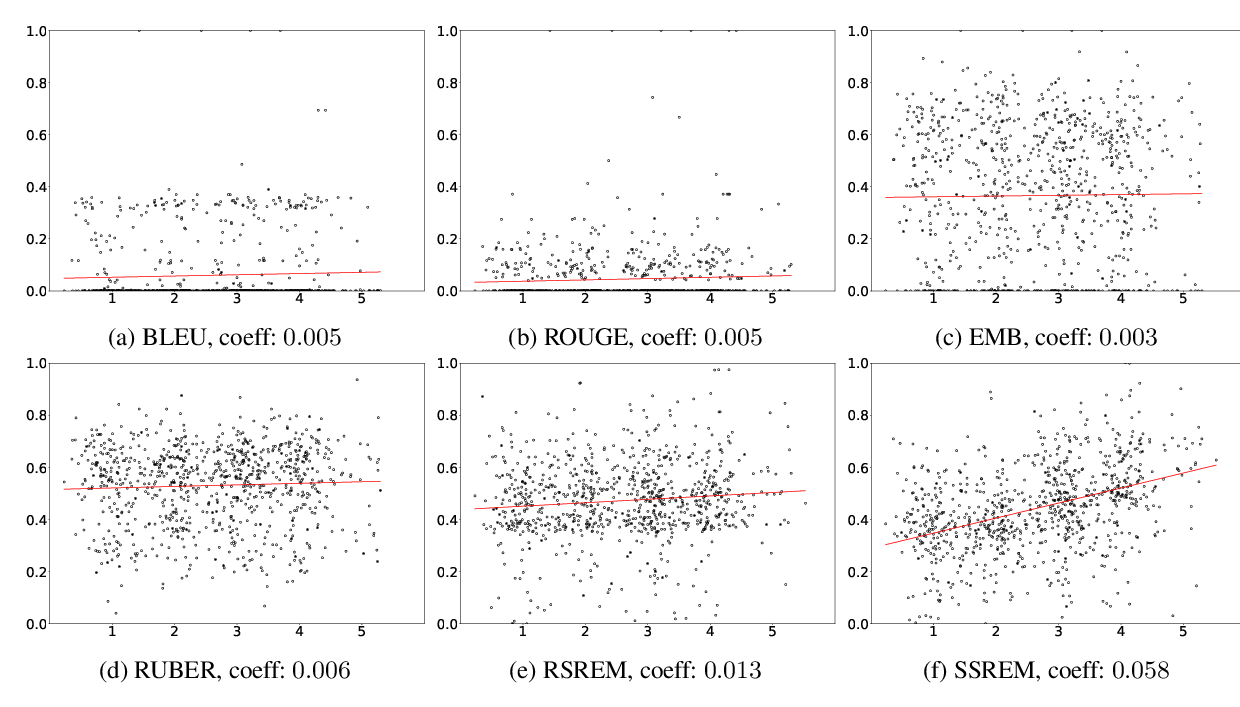
Existing automatic evaluation metrics for open-domain dialogue response generation systems correlate poorly with human evaluation. We focus on evaluating response generation systems via response selection. To evaluate systems properly via response selection, we propose a method to construct response selection test sets with well-chosen false candidates. Specifically, we propose to construct test sets filtering out some types of false candidates: (i) those unrelated to the ground-truth response and (ii) those acceptable as appropriate responses. Through experiments, we demonstrate that evaluating systems via response selection with the test set developed by our method correlates more strongly with human evaluation, compared with widely used automatic evaluation metrics such as BLEU.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
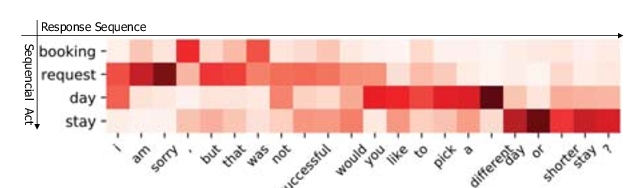
Multi-Domain Dialogue Acts and Response Co-Generation
Kai Wang, Junfeng Tian, Rui Wang, Xiaojun Quan, Jianxing Yu,