Beyond User Self-Reported Likert Scale Ratings: A Comparison Model for Automatic Dialog Evaluation
Weixin Liang, James Zou, Zhou Yu
Dialogue and Interactive Systems Long Paper
Session 2B: Jul 6
(09:00-10:00 GMT)

Session 3A: Jul 6
(12:00-13:00 GMT)
Abstract:
Open Domain dialog system evaluation is one of the most important challenges in dialog research. Existing automatic evaluation metrics, such as BLEU are mostly reference-based. They calculate the difference between the generated response and a limited number of available references. Likert-score based self-reported user rating is widely adopted by social conversational systems, such as Amazon Alexa Prize chatbots. However, self-reported user rating suffers from bias and variance among different users. To alleviate this problem, we formulate dialog evaluation as a comparison task. We also propose an automatic evaluation model CMADE (Comparison Model for Automatic Dialog Evaluation) that automatically cleans self-reported user ratings as it trains on them. Specifically, we first use a self-supervised method to learn better dialog feature representation, and then use KNN and Shapley to remove confusing samples. Our experiments show that CMADE achieves 89.2% accuracy in the dialog comparison task.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
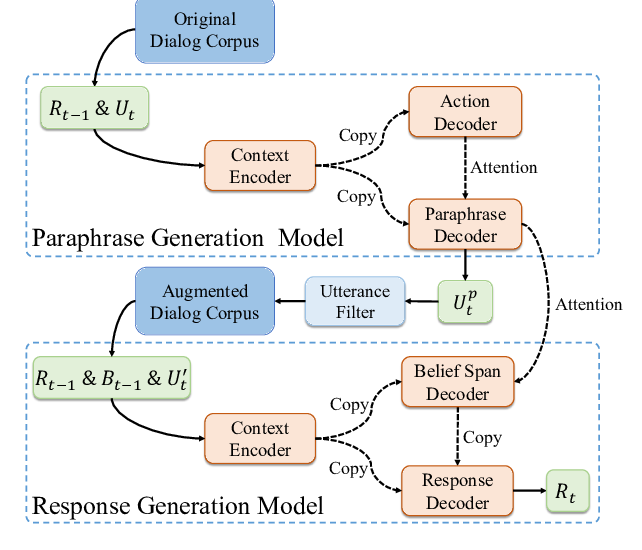
Conversation Learner - A Machine Teaching Tool for Building Dialog Managers for Task-Oriented Dialog Systems
Swadheen Shukla, Lars Liden, Shahin Shayandeh, Eslam Kamal, Jinchao Li, Matt Mazzola, Thomas Park, Baolin Peng, Jianfeng Gao,
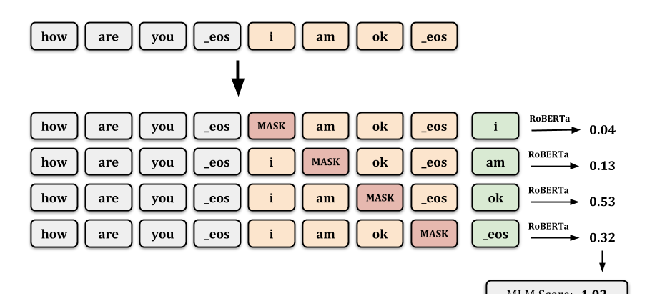
USR: An Unsupervised and Reference Free Evaluation Metric for Dialog Generation
Shikib Mehri, Maxine Eskenazi,
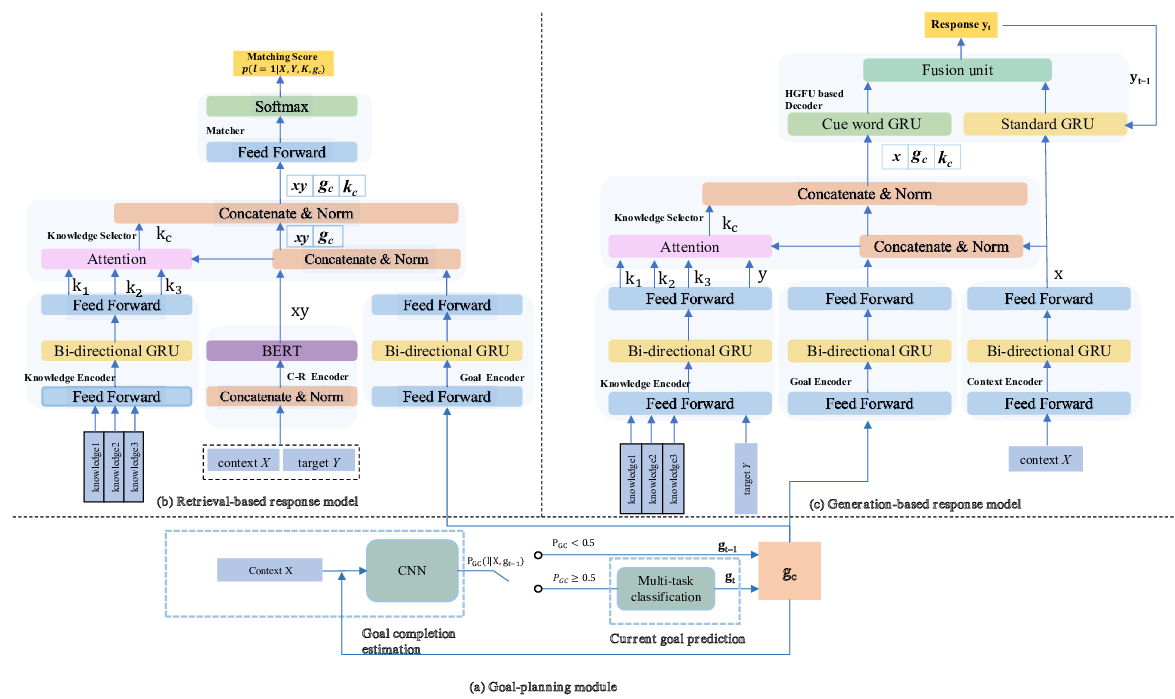
Towards Conversational Recommendation over Multi-Type Dialogs
Zeming Liu, Haifeng Wang, Zheng-Yu Niu, Hua Wu, Wanxiang Che, Ting Liu,