Can We Predict New Facts with Open Knowledge Graph Embeddings? A Benchmark for Open Link Prediction
Samuel Broscheit, Kiril Gashteovski, Yanjie Wang, Rainer Gemulla
Semantics: Textual Inference and Other Areas of Semantics Long Paper
Session 4A: Jul 6
(17:00-18:00 GMT)

Session 5A: Jul 6
(20:00-21:00 GMT)
Abstract:
Open Information Extraction systems extract (“subject text”, “relation text”, “object text”) triples from raw text. Some triples are textual versions of facts, i.e., non-canonicalized mentions of entities and relations. In this paper, we investigate whether it is possible to infer new facts directly from the open knowledge graph without any canonicalization or any supervision from curated knowledge. For this purpose, we propose the open link prediction task,i.e., predicting test facts by completing (“subject text”, “relation text”, ?) questions. An evaluation in such a setup raises the question if a correct prediction is actually a new fact that was induced by reasoning over the open knowledge graph or if it can be trivially explained. For example, facts can appear in different paraphrased textual variants, which can lead to test leakage. To this end, we propose an evaluation protocol and a methodology for creating the open link prediction benchmark OlpBench. We performed experiments with a prototypical knowledge graph embedding model for openlink prediction. While the task is very challenging, our results suggests that it is possible to predict genuinely new facts, which can not be trivially explained.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Predicting the Growth of Morphological Families from Social and Linguistic Factors
Valentin Hofmann, Janet Pierrehumbert, Hinrich Schütze,
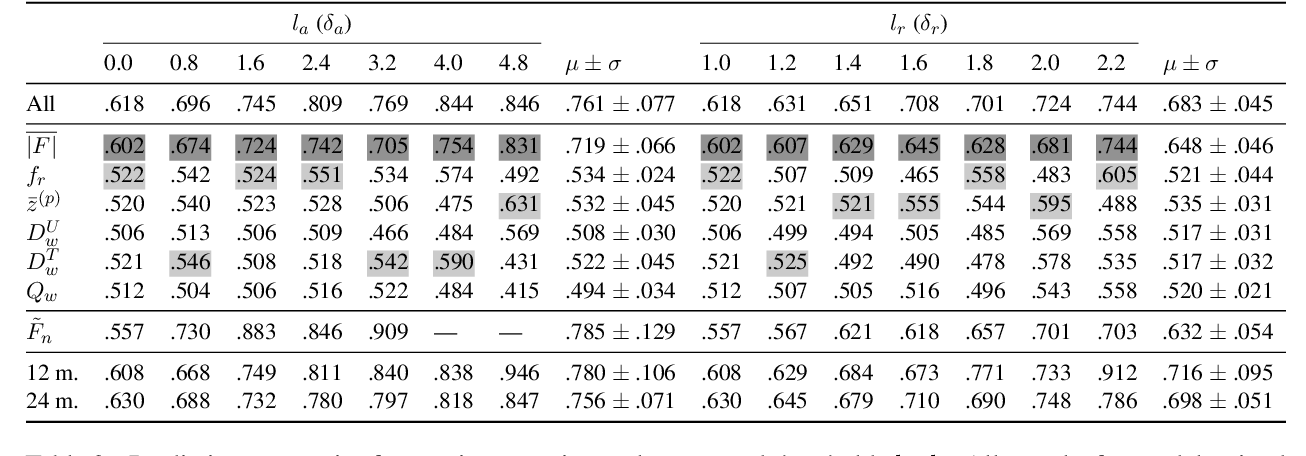
Diverse and Informative Dialogue Generation with Context-Specific Commonsense Knowledge Awareness
Sixing Wu, Ying Li, Dawei Zhang, Yang Zhou, Zhonghai Wu,
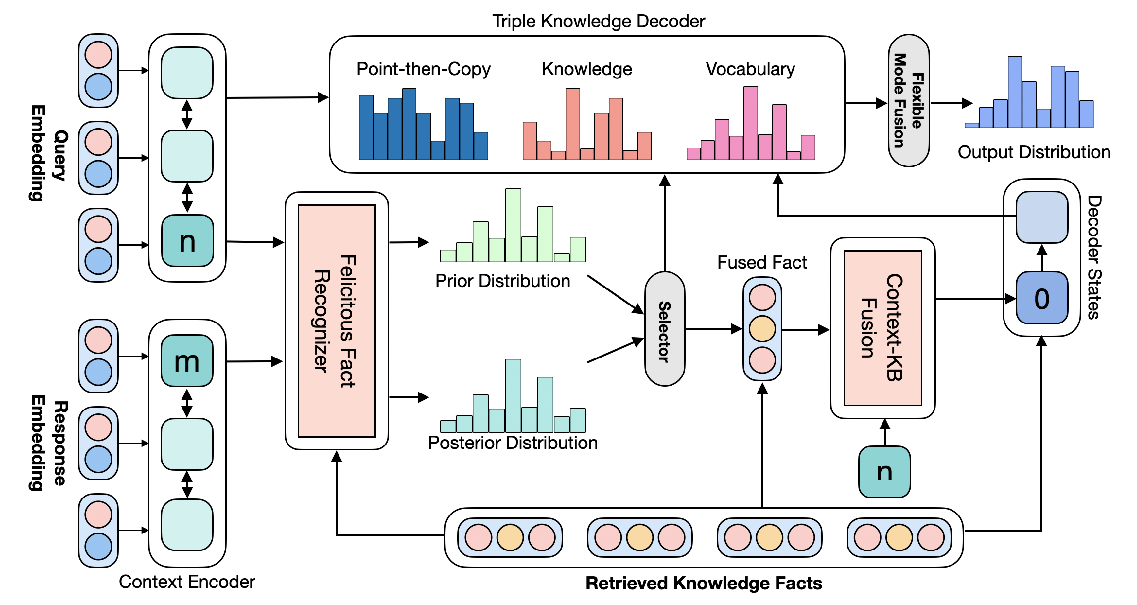
NeuInfer: Knowledge Inference on N-ary Facts
Saiping Guan, Xiaolong Jin, Jiafeng Guo, Yuanzhuo Wang, Xueqi Cheng,
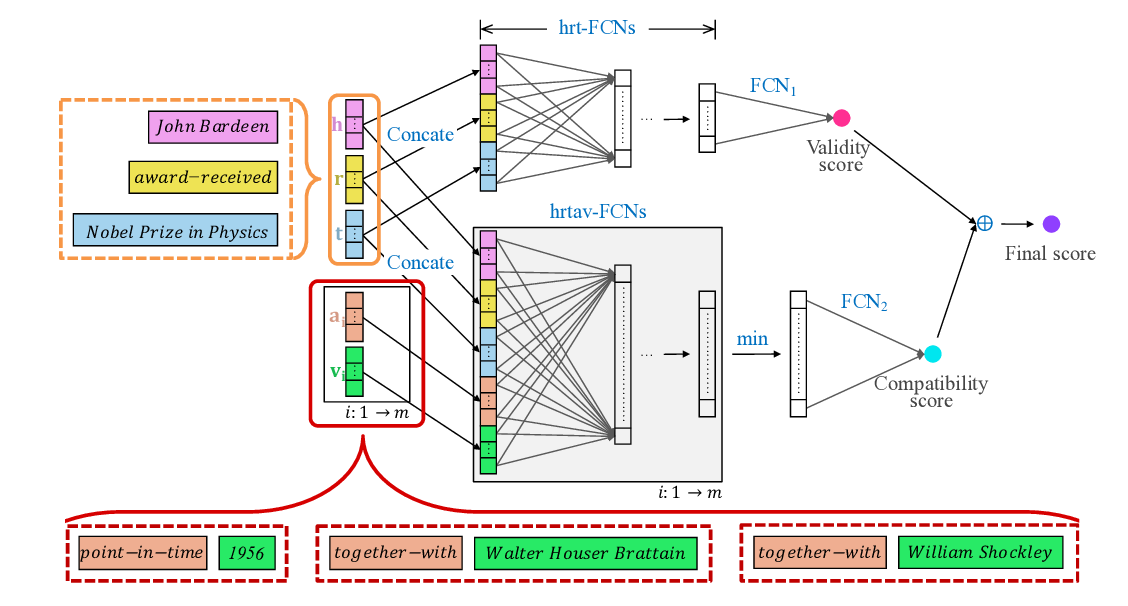
Learning Interpretable Relationships between Entities, Relations and Concepts via Bayesian Structure Learning on Open Domain Facts
Jingyuan Zhang, Mingming Sun, Yue Feng, Ping Li,