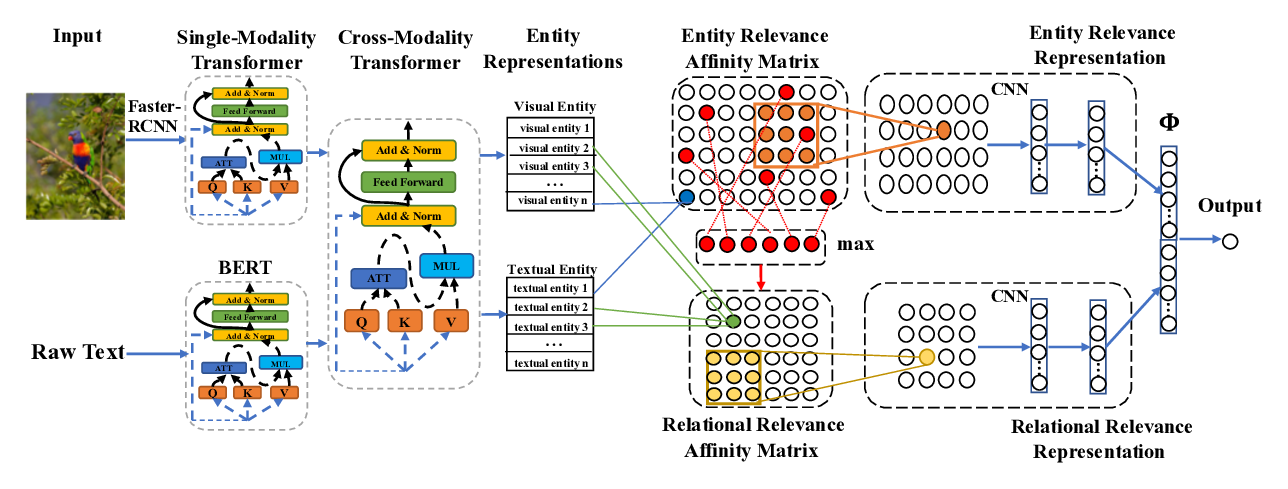
Cross-media Structured Common Space for Multimedia Event Extraction
Manling Li, Alireza Zareian, Qi Zeng, Spencer Whitehead, Di Lu, Heng Ji, Shih-Fu Chang
Language Grounding to Vision, Robotics and Beyond Long Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5B: Jul 6
(21:00-22:00 GMT)
Abstract:
We introduce a new task, MultiMedia Event Extraction, which aims to extract events and their arguments from multimedia documents. We develop the first benchmark and collect a dataset of 245 multimedia news articles with extensively annotated events and arguments. We propose a novel method, Weakly Aligned Structured Embedding (WASE), that encodes structured representations of semantic information from textual and visual data into a common embedding space. The structures are aligned across modalities by employing a weakly supervised training strategy, which enables exploiting available resources without explicit cross-media annotation. Compared to uni-modal state-of-the-art methods, our approach achieves 4.0% and 9.8% absolute F-score gains on text event argument role labeling and visual event extraction. Compared to state-of-the-art multimedia unstructured representations, we achieve 8.3% and 5.0% absolute F-score gains on multimedia event extraction and argument role labeling, respectively. By utilizing images, we extract 21.4% more event mentions than traditional text-only methods.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
GAIA: A Fine-grained Multimedia Knowledge Extraction System
Manling Li, Alireza Zareian, Ying Lin, Xiaoman Pan, Spencer Whitehead, Brian Chen, Bo Wu, Heng Ji, Shih-Fu Chang, Clare Voss, Daniel Napierski, Marjorie Freedman,
TransS-Driven Joint Learning Architecture for Implicit Discourse Relation Recognition
Ruifang He, Jian Wang, Fengyu Guo, Yugui Han,
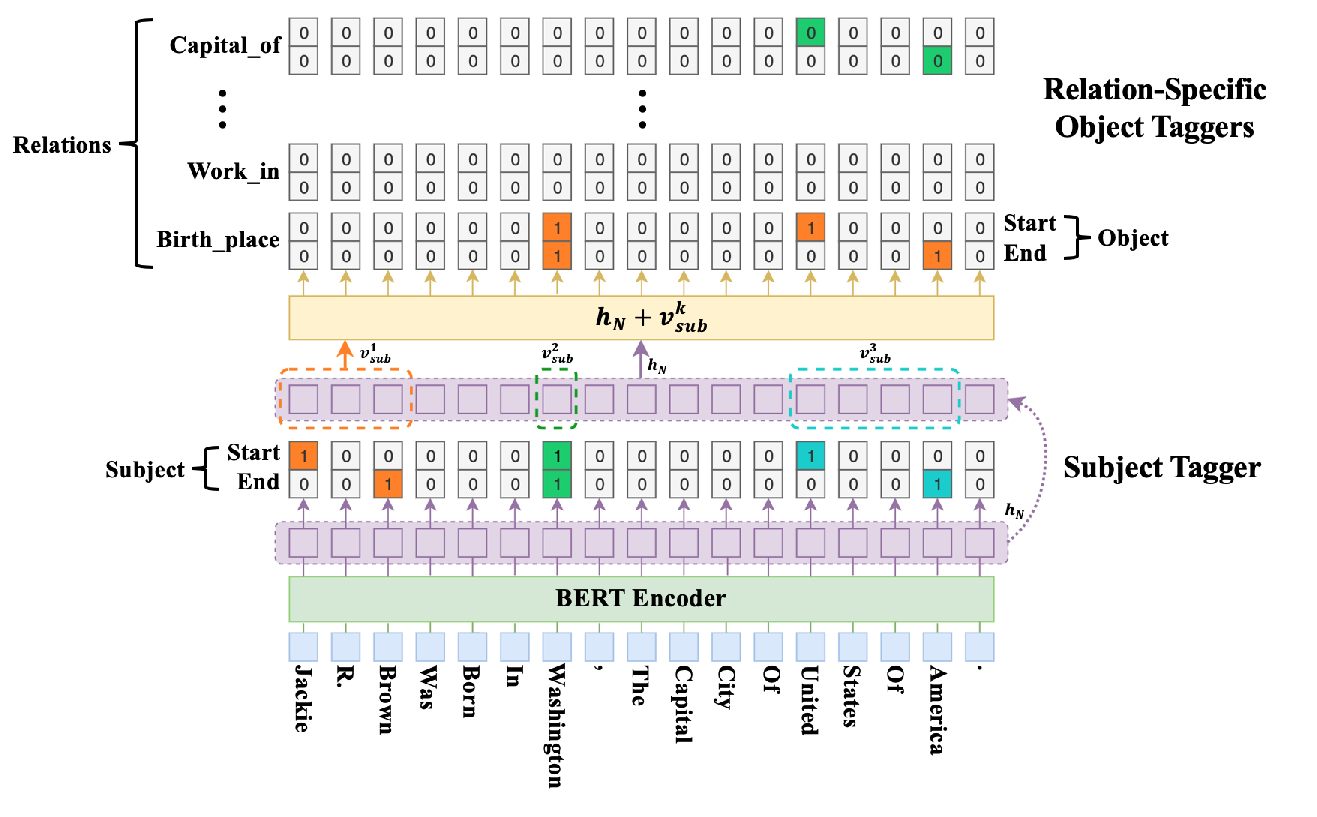
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
Zhepei Wei, Jianlin Su, Yue Wang, Yuan Tian, Yi Chang,
Cross-Modality Relevance for Reasoning on Language and Vision
Chen Zheng, Quan Guo, Parisa Kordjamshidi,