Knowledge Graph Embedding Compression
Mrinmaya Sachan
Machine Learning for NLP Long Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5B: Jul 6
(21:00-22:00 GMT)
Abstract:
Knowledge graph (KG) representation learning techniques that learn continuous embeddings of entities and relations in the KG have become popular in many AI applications. With a large KG, the embeddings consume a large amount of storage and memory. This is problematic and prohibits the deployment of these techniques in many real world settings. Thus, we propose an approach that compresses the KG embedding layer by representing each entity in the KG as a vector of discrete codes and then composes the embeddings from these codes. The approach can be trained end-to-end with simple modifications to any existing KG embedding technique. We evaluate the approach on various standard KG embedding evaluations and show that it achieves 50-1000x compression of embeddings with a minor loss in performance. The compressed embeddings also retain the ability to perform various reasoning tasks such as KG inference.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
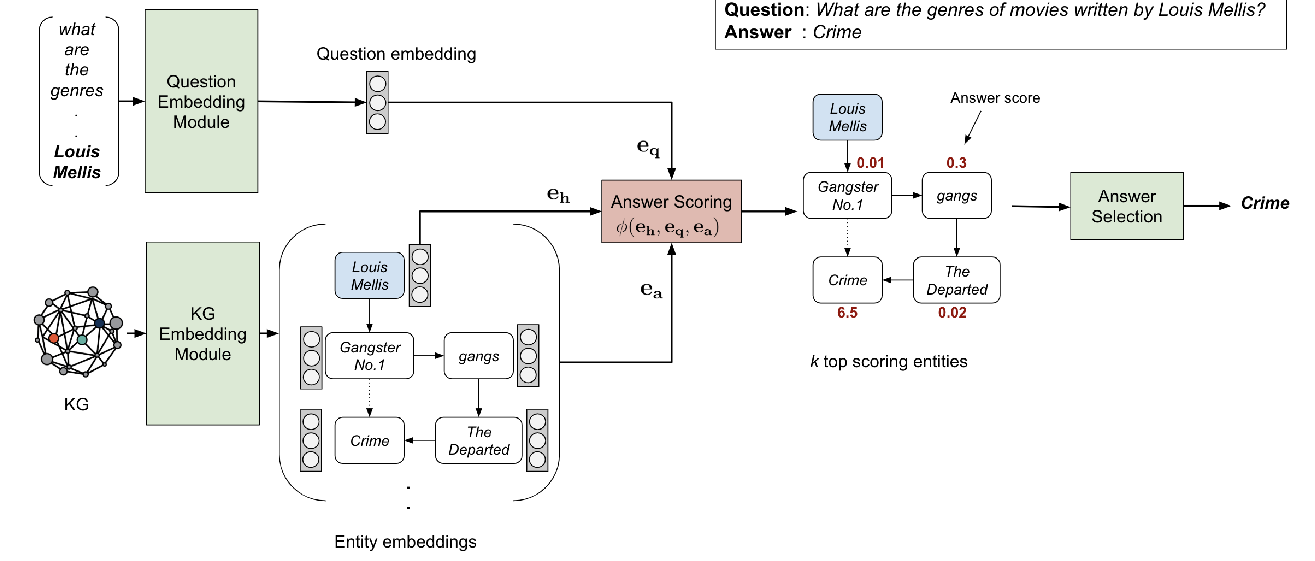
Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings
Apoorv Saxena, Aditay Tripathi, Partha Talukdar,
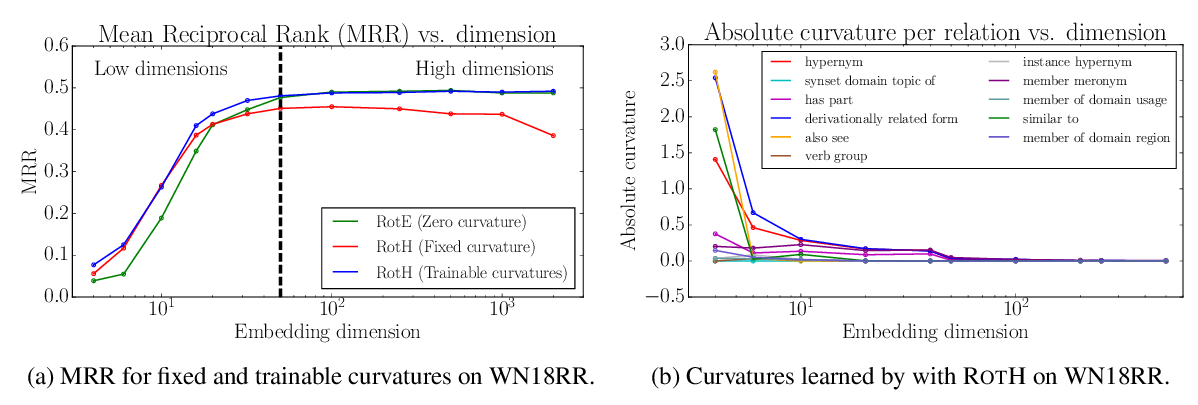
Low-Dimensional Hyperbolic Knowledge Graph Embeddings
Ines Chami, Adva Wolf, Da-Cheng Juan, Frederic Sala, Sujith Ravi, Christopher Ré,
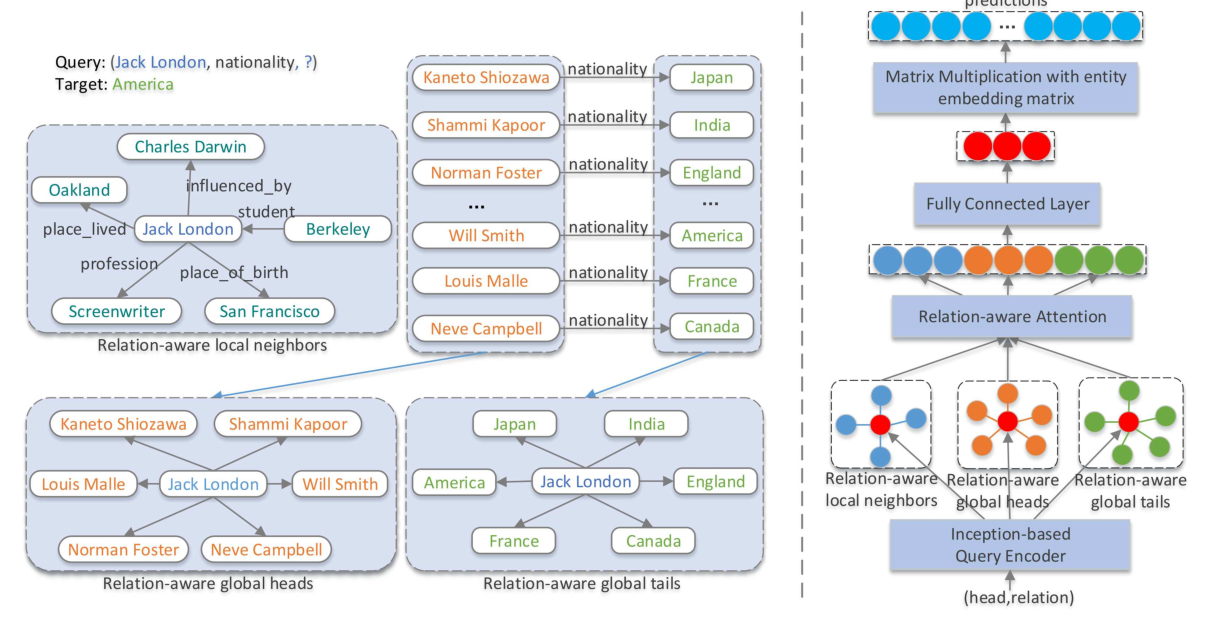
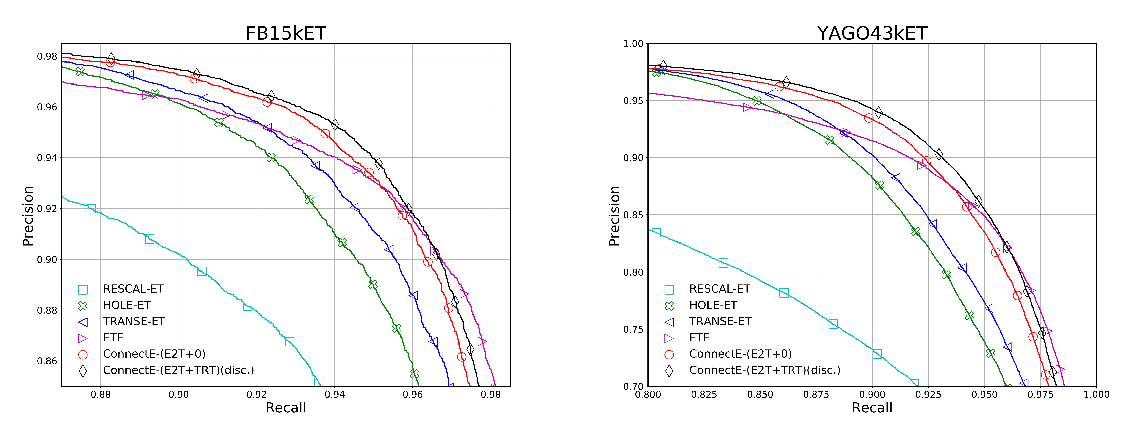
Connecting Embeddings for Knowledge Graph Entity Typing
Yu Zhao, anxiang zhang, Ruobing Xie, Kang Liu, Xiaojie WANG,
ReInceptionE: Relation-Aware Inception Network with Joint Local-Global Structural Information for Knowledge Graph Embedding
Zhiwen Xie, Guangyou Zhou, Jin Liu, Jimmy Xiangji Huang,