MOOCCube: A Large-scale Data Repository for NLP Applications in MOOCs
Jifan Yu, Gan Luo, Tong Xiao, Qingyang Zhong, Yuquan Wang, Wenzheng Feng, Junyi Luo, Chenyu Wang, Lei Hou, Juanzi Li, Zhiyuan Liu, Jie Tang
NLP Applications Short Paper
Session 6A: Jul 7
(05:00-06:00 GMT)

Session 7B: Jul 7
(09:00-10:00 GMT)
Abstract:
The prosperity of Massive Open Online Courses (MOOCs) provides fodder for many NLP and AI research for education applications, e.g., course concept extraction, prerequisite relation discovery, etc. However, the publicly available datasets of MOOC are limited in size with few types of data, which hinders advanced models and novel attempts in related topics. Therefore, we present MOOCCube, a large-scale data repository of over 700 MOOC courses, 100k concepts, 8 million student behaviors with an external resource. Moreover, we conduct a prerequisite discovery task as an example application to show the potential of MOOCCube in facilitating relevant research. The data repository is now available at http://moocdata.cn/data/MOOCCube.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
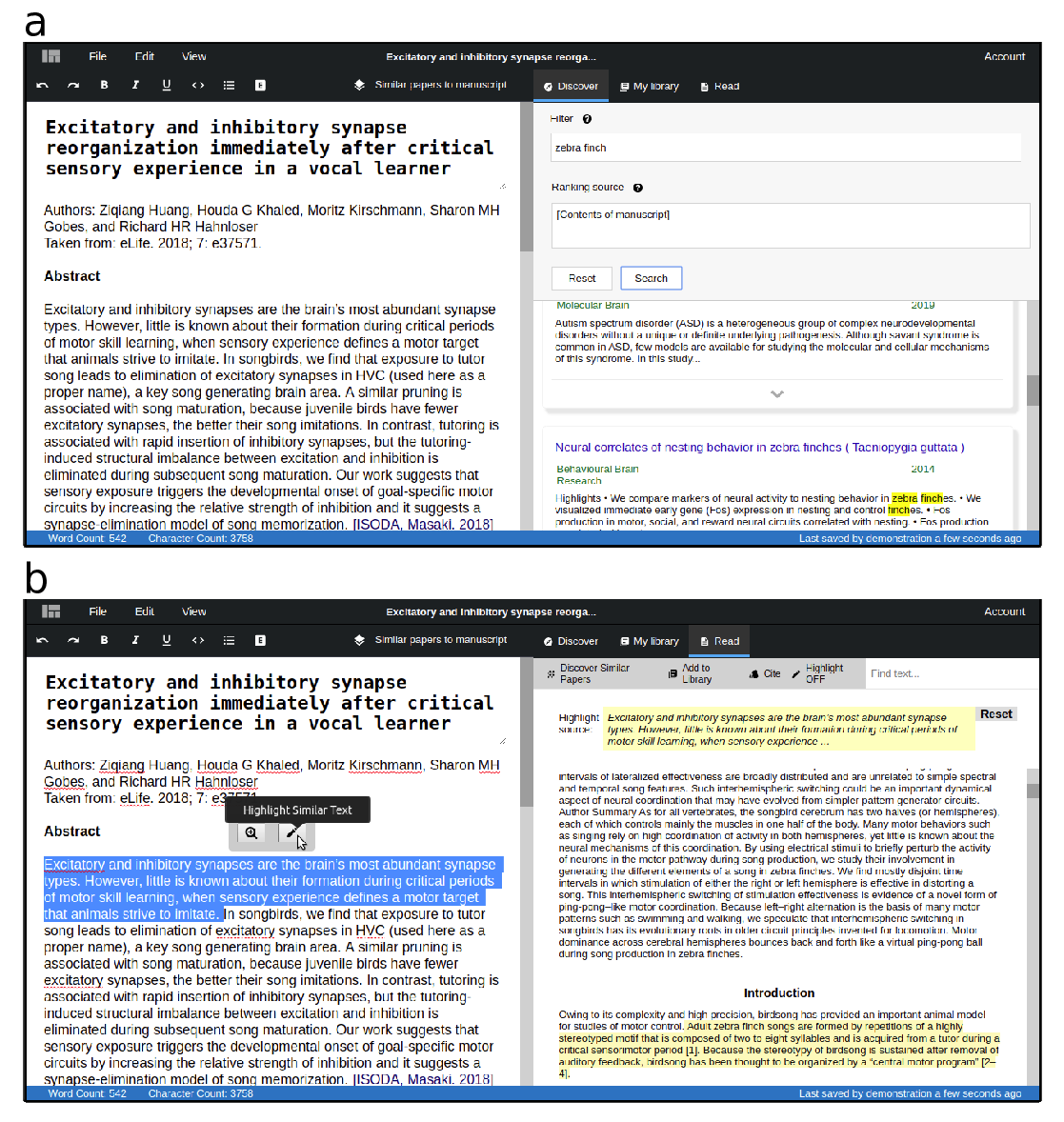
Embedding-based Scientific Literature Discovery in a Text Editor Application
Onur Gökçe, Jonathan Prada, Nikola I. Nikolov, Nianlong Gu, Richard H.R. Hahnloser,
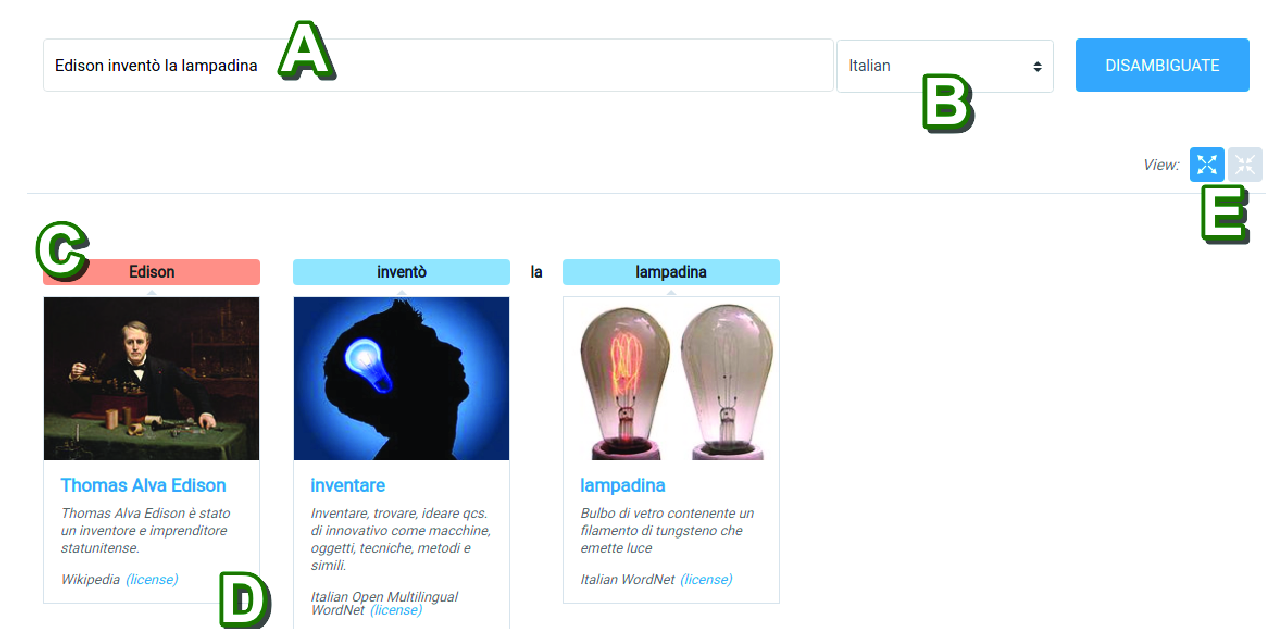
Personalized PageRank with Syntagmatic Information for Multilingual Word Sense Disambiguation
Federico Scozzafava, Marco Maru, Fabrizio Brignone, Giovanni Torrisi, Roberto Navigli,
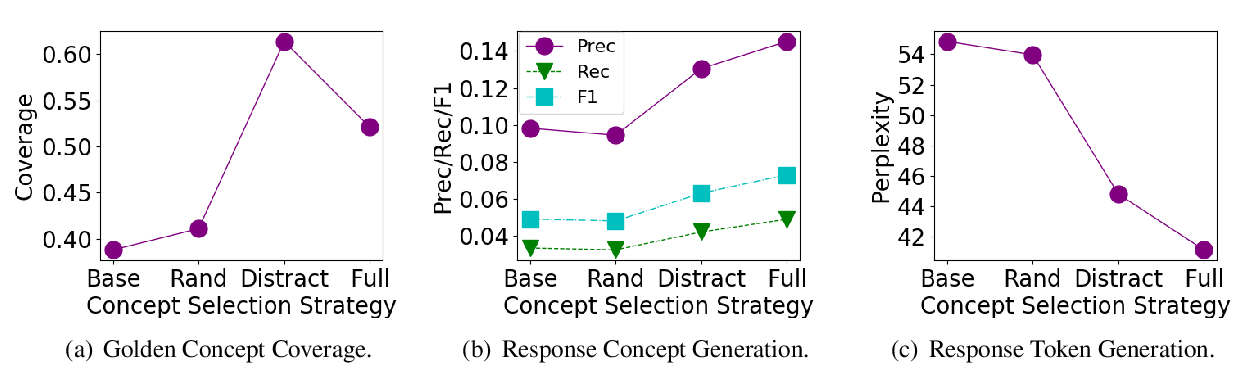
Grounded Conversation Generation as Guided Traverses in Commonsense Knowledge Graphs
Houyu Zhang, Zhenghao Liu, Chenyan Xiong, Zhiyuan Liu,
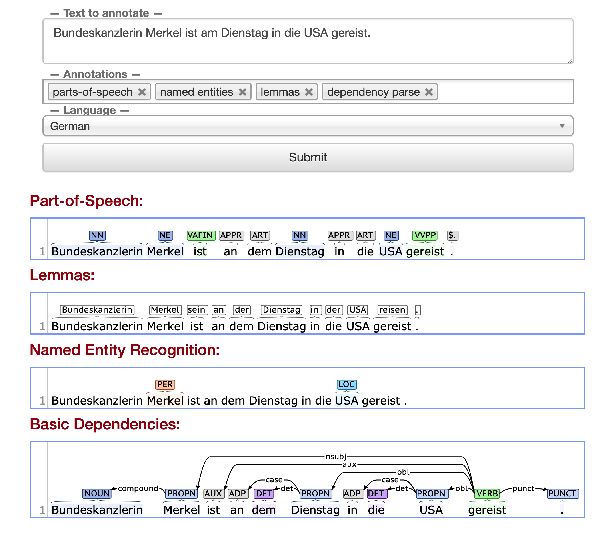
Stanza: A Python Natural Language Processing Toolkit for Many Human Languages
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, Christopher D. Manning,