Stanza: A Python Natural Language Processing Toolkit for Many Human Languages
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, Christopher D. Manning
System Demonstrations Demo Paper
Demo Session 4B-1: Jul 6
(17:45-18:45 GMT)

Demo Session 5C-1: Jul 6
(21:30-22:30 GMT)
Abstract:
We introduce Stanza, an open-source Python natural language processing toolkit supporting 66 human languages. Compared to existing widely used toolkits, Stanza features a language-agnostic fully neural pipeline for text analysis, including tokenization, multi-word token expansion, lemmatization, part-of-speech and morphological feature tagging, dependency parsing, and named entity recognition. We have trained Stanza on a total of 112 datasets, including the Universal Dependencies treebanks and other multilingual corpora, and show that the same neural architecture generalizes well and achieves competitive performance on all languages tested. Additionally, Stanza includes a native Python interface to the widely used Java Stanford CoreNLP software, which further extends its functionality to cover other tasks such as coreference resolution and relation extraction. Source code, documentation, and pretrained models for 66 languages are available at https://stanfordnlp.github.io/stanza/.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Personalized PageRank with Syntagmatic Information for Multilingual Word Sense Disambiguation
Federico Scozzafava, Marco Maru, Fabrizio Brignone, Giovanni Torrisi, Roberto Navigli,
ESPnet-ST: All-in-One Speech Translation Toolkit
Hirofumi Inaguma, Shun Kiyono, Kevin Duh, Shigeki Karita, Nelson Yalta, Tomoki Hayashi, Shinji Watanabe,
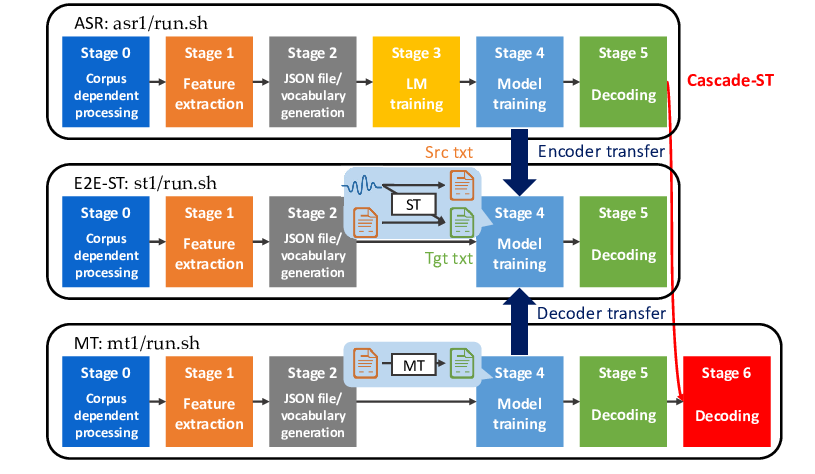
Code and Named Entity Recognition in StackOverflow
Jeniya Tabassum, Mounica Maddela, Wei Xu, Alan Ritter,