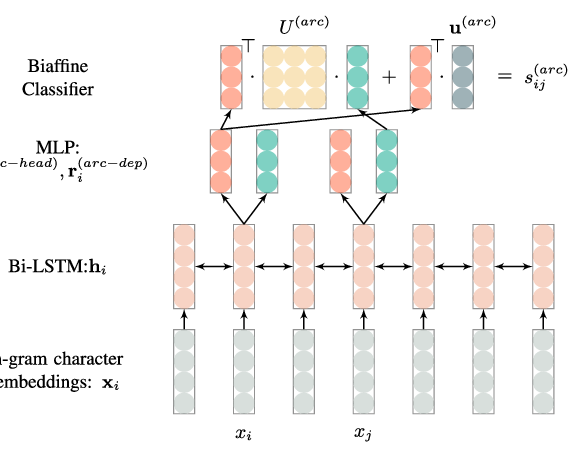
Efficient Second-Order TreeCRF for Neural Dependency Parsing
Yu Zhang, Zhenghua Li, Min Zhang
Syntax: Tagging, Chunking and Parsing Long Paper
Session 6A: Jul 7
(05:00-06:00 GMT)

Session 7A: Jul 7
(08:00-09:00 GMT)
Abstract:
In the deep learning (DL) era, parsing models are extremely simplified with little hurt on performance, thanks to the remarkable capability of multi-layer BiLSTMs in context representation. As the most popular graph-based dependency parser due to its high efficiency and performance, the biaffine parser directly scores single dependencies under the arc-factorization assumption, and adopts a very simple local token-wise cross-entropy training loss. This paper for the first time presents a second-order TreeCRF extension to the biaffine parser. For a long time, the complexity and inefficiency of the inside-outside algorithm hinder the popularity of TreeCRF. To address this issue, we propose an effective way to batchify the inside and Viterbi algorithms for direct large matrix operation on GPUs, and to avoid the complex outside algorithm via efficient back-propagation. Experiments and analysis on 27 datasets from 13 languages clearly show that techniques developed before the DL era, such as structural learning (global TreeCRF loss) and high-order modeling are still useful, and can further boost parsing performance over the state-of-the-art biaffine parser, especially for partially annotated training data. We release our code at https://github.com/yzhangcs/crfpar.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
SEEK: Segmented Embedding of Knowledge Graphs
Wentao Xu, Shun Zheng, Liang He, Bin Shao, Jian Yin, Tie-Yan Liu,
A Graph-based Model for Joint Chinese Word Segmentation and Dependency Parsing
Hang Yan, Xipeng Qiu, Xuanjing Huang,
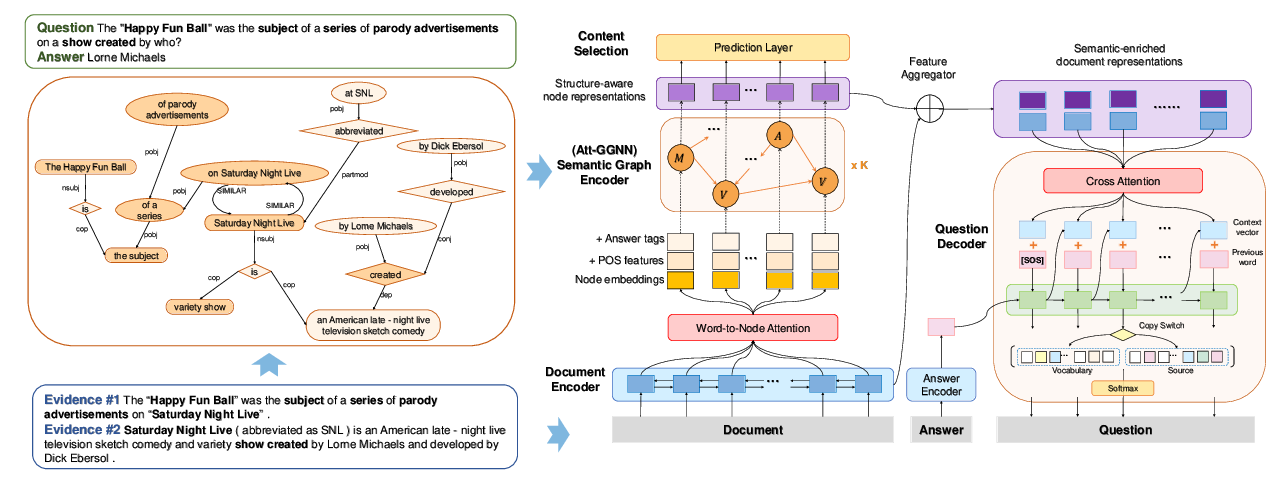
Semantic Graphs for Generating Deep Questions
Liangming Pan, Yuxi Xie, Yansong Feng, Tat-Seng Chua, Min-Yen Kan,