S2ORC: The Semantic Scholar Open Research Corpus
Kyle Lo, Lucy Wang, Mark Neumann, Rodney Kinney, Daniel Weld
Resources and Evaluation Long Paper
Session 9A: Jul 7
(17:00-18:00 GMT)

Session 10B: Jul 7
(21:00-22:00 GMT)
Abstract:
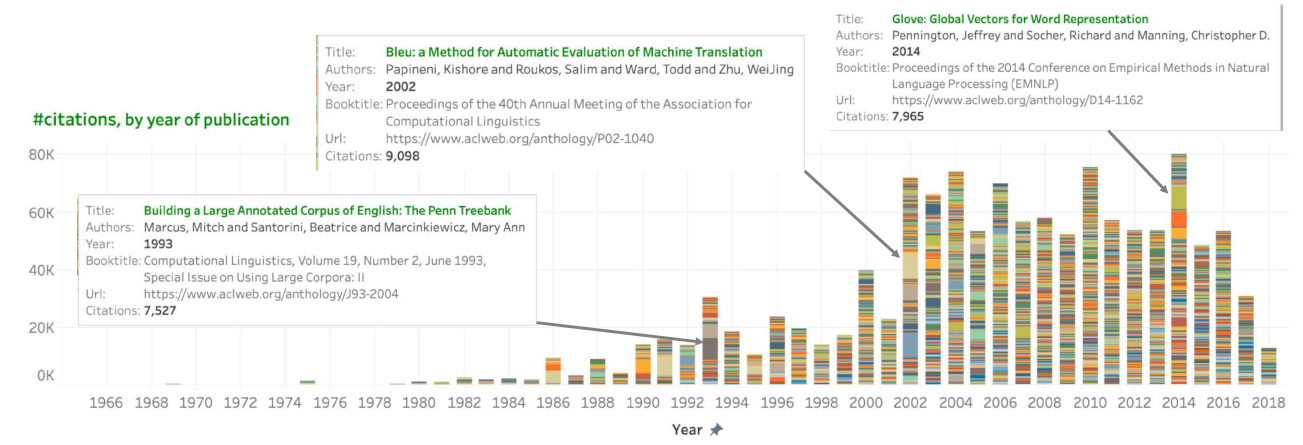
We introduce S2ORC, a large corpus of 81.1M English-language academic papers spanning many academic disciplines. The corpus consists of rich metadata, paper abstracts, resolved bibliographic references, as well as structured full text for 8.1M open access papers. Full text is annotated with automatically-detected inline mentions of citations, figures, and tables, each linked to their corresponding paper objects. In S2ORC, we aggregate papers from hundreds of academic publishers and digital archives into a unified source, and create the largest publicly-available collection of machine-readable academic text to date. We hope this resource will facilitate research and development of tools and tasks for text mining over academic text.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers

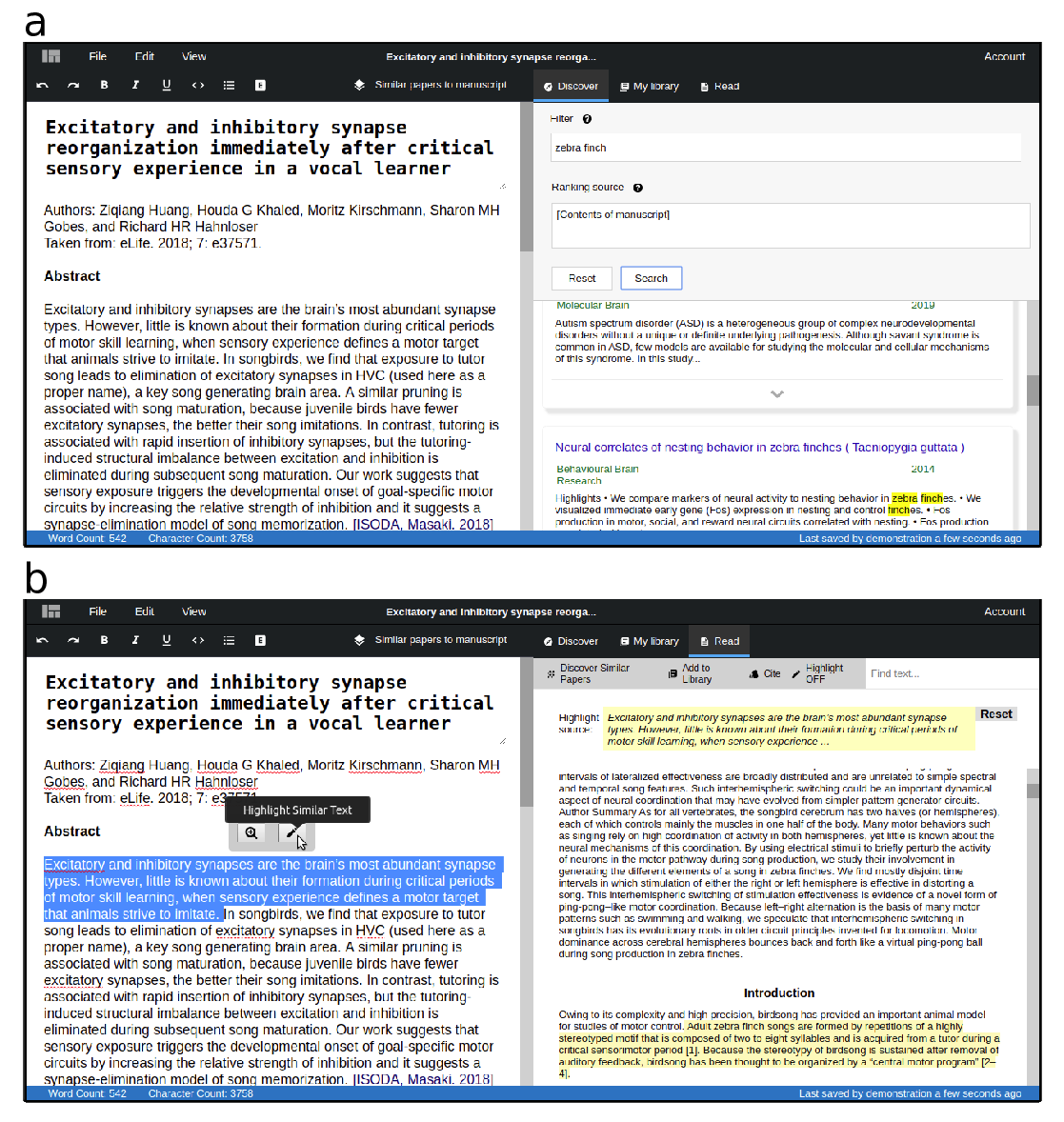
Embedding-based Scientific Literature Discovery in a Text Editor Application
Onur Gökçe, Jonathan Prada, Nikola I. Nikolov, Nianlong Gu, Richard H.R. Hahnloser,
TextBrewer: An Open-Source Knowledge Distillation Toolkit for Natural Language Processing
Ziqing Yang, Yiming Cui, Zhipeng Chen, Wanxiang Che, Ting Liu, Shijin Wang, Guoping Hu,
