Words Aren't Enough, Their Order Matters: On the Robustness of Grounding Visual Referring Expressions
Arjun Akula, Spandana Gella, Yaser Al-Onaizan, Song-Chun Zhu, Siva Reddy
Language Grounding to Vision, Robotics and Beyond Short Paper
Session 11B: Jul 8
(06:00-07:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
Visual referring expression recognition is a challenging task that requires natural language understanding in the context of an image. We critically examine RefCOCOg, a standard benchmark for this task, using a human study and show that 83.7% of test instances do not require reasoning on linguistic structure, i.e., words are enough to identify the target object, the word order doesn't matter. To measure the true progress of existing models, we split the test set into two sets, one which requires reasoning on linguistic structure and the other which doesn’t. Additionally, we create an out-of-distribution dataset Ref-Adv by asking crowdworkers to perturb in-domain examples such that the target object changes. Using these datasets, we empirically show that existing methods fail to exploit linguistic structure and are 12% to 23% lower in performance than the established progress for this task. We also propose two methods, one based on contrastive learning and the other based on multi-task learning, to increase the robustness of ViLBERT, the current state-of-the-art model for this task. Our datasets are publicly available at https://github.com/aws/aws-refcocog-adv.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
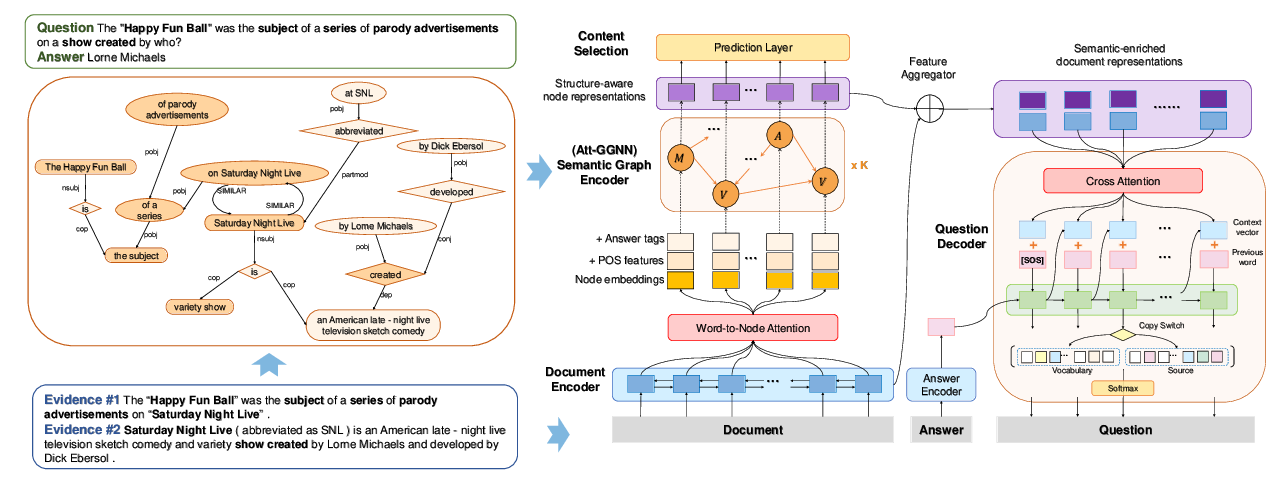
Semantic Graphs for Generating Deep Questions
Liangming Pan, Yuxi Xie, Yansong Feng, Tat-Seng Chua, Min-Yen Kan,
PuzzLing Machines: A Challenge on Learning From Small Data
Gözde Gül Şahin, Yova Kementchedjhieva, Phillip Rust, Iryna Gurevych,
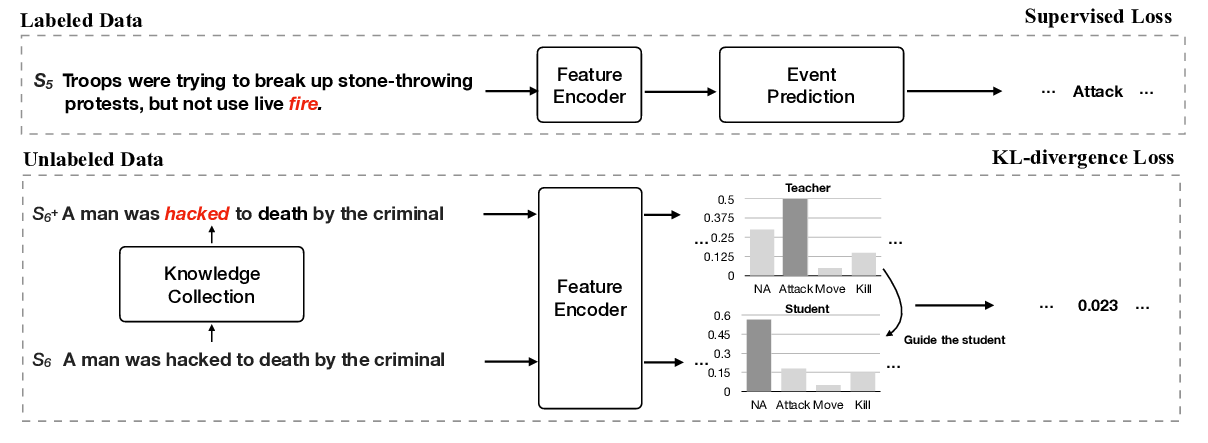
Improving Event Detection via Open-domain Trigger Knowledge
Meihan Tong, Bin Xu, Shuai Wang, Yixin Cao, Lei Hou, Juanzi Li, Jun Xie,
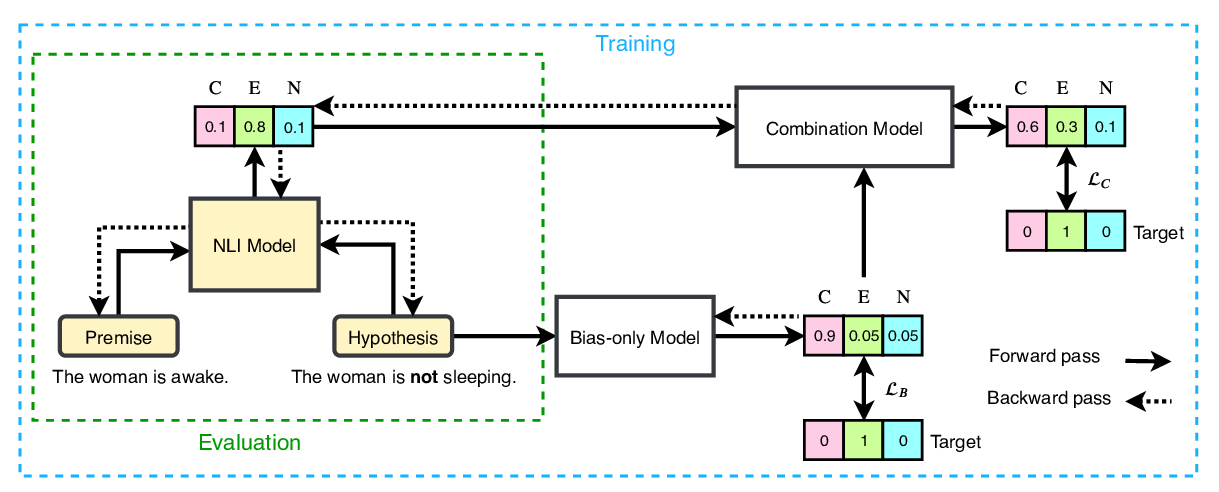
End-to-End Bias Mitigation by Modelling Biases in Corpora
Rabeeh Karimi Mahabadi, Yonatan Belinkov, James Henderson,