End-to-End Bias Mitigation by Modelling Biases in Corpora
Rabeeh Karimi Mahabadi, Yonatan Belinkov, James Henderson
Semantics: Textual Inference and Other Areas of Semantics Long Paper
Session 14B: Jul 8
(18:00-19:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
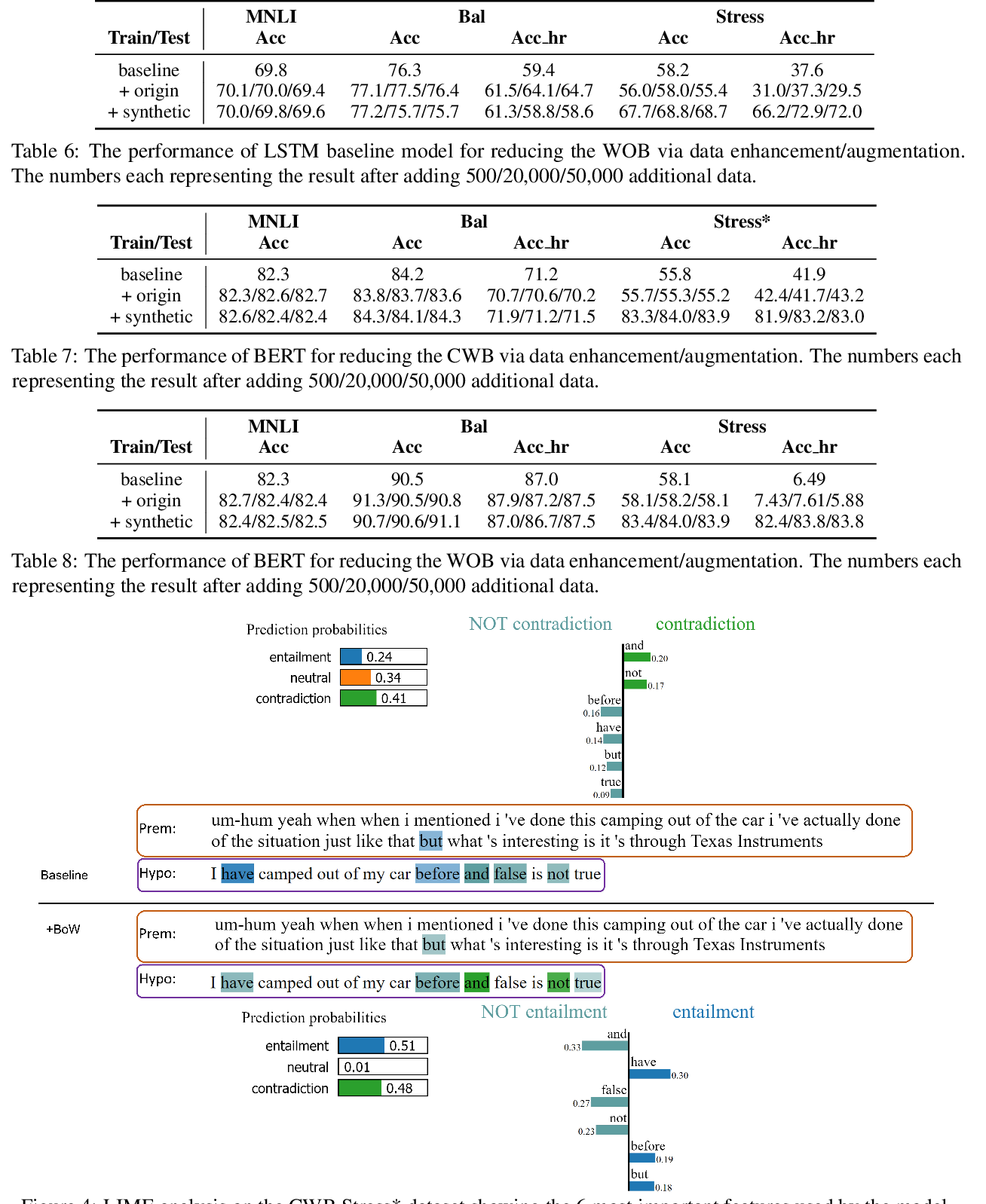
Several recent studies have shown that strong natural language understanding (NLU) models are prone to relying on unwanted dataset biases without learning the underlying task, resulting in models that fail to generalize to out-of-domain datasets and are likely to perform poorly in real-world scenarios. We propose two learning strategies to train neural models, which are more robust to such biases and transfer better to out-of-domain datasets. The biases are specified in terms of one or more bias-only models, which learn to leverage the dataset biases. During training, the bias-only models' predictions are used to adjust the loss of the base model to reduce its reliance on biases by down-weighting the biased examples and focusing the training on the hard examples. We experiment on large-scale natural language inference and fact verification benchmarks, evaluating on out-of-domain datasets that are specifically designed to assess the robustness of models against known biases in the training data. Results show that our debiasing methods greatly improve robustness in all settings and better transfer to other textual entailment datasets. Our code and data are publicly available in https://github.com/rabeehk/robust-nli.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
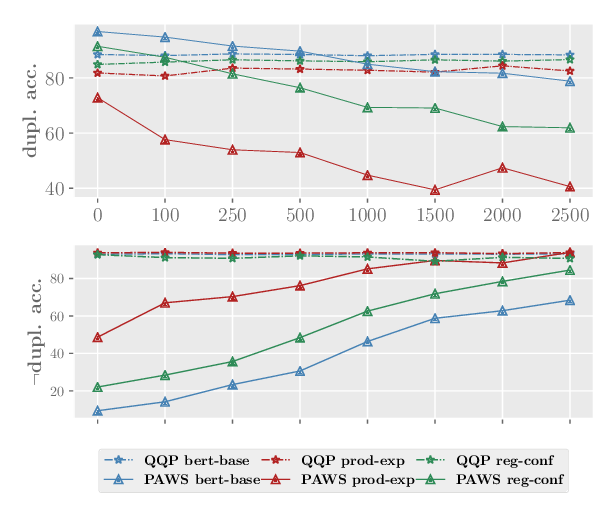
Mind the Trade-off: Debiasing NLU Models without Degrading the In-distribution Performance
Prasetya Ajie Utama, Nafise Sadat Moosavi, Iryna Gurevych,
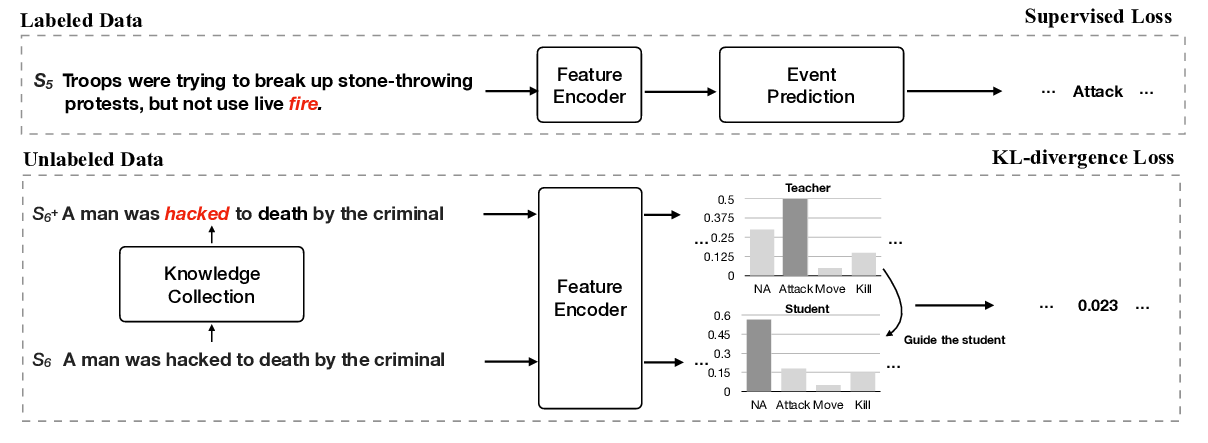
Improving Event Detection via Open-domain Trigger Knowledge
Meihan Tong, Bin Xu, Shuai Wang, Yixin Cao, Lei Hou, Juanzi Li, Jun Xie,
Words Aren't Enough, Their Order Matters: On the Robustness of Grounding Visual Referring Expressions
Arjun Akula, Spandana Gella, Yaser Al-Onaizan, Song-Chun Zhu, Siva Reddy,