Should All Cross-Lingual Embeddings Speak English?
Antonios Anastasopoulos, Graham Neubig
NLP Applications Long Paper
Session 14B: Jul 8
(18:00-19:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
Most of recent work in cross-lingual word embeddings is severely Anglocentric. The vast majority of lexicon induction evaluation dictionaries are between English and another language, and the English embedding space is selected by default as the hub when learning in a multilingual setting. With this work, however, we challenge these practices. First, we show that the choice of hub language can significantly impact downstream lexicon induction zero-shot POS tagging performance. Second, we both expand a standard English-centered evaluation dictionary collection to include all language pairs using triangulation, and create new dictionaries for under-represented languages. Evaluating established methods over all these language pairs sheds light into their suitability for aligning embeddings from distant languages and presents new challenges for the field. Finally, in our analysis we identify general guidelines for strong cross-lingual embedding baselines, that extend to language pairs that do not include English.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
On the Cross-lingual Transferability of Monolingual Representations
Mikel Artetxe, Sebastian Ruder, Dani Yogatama,
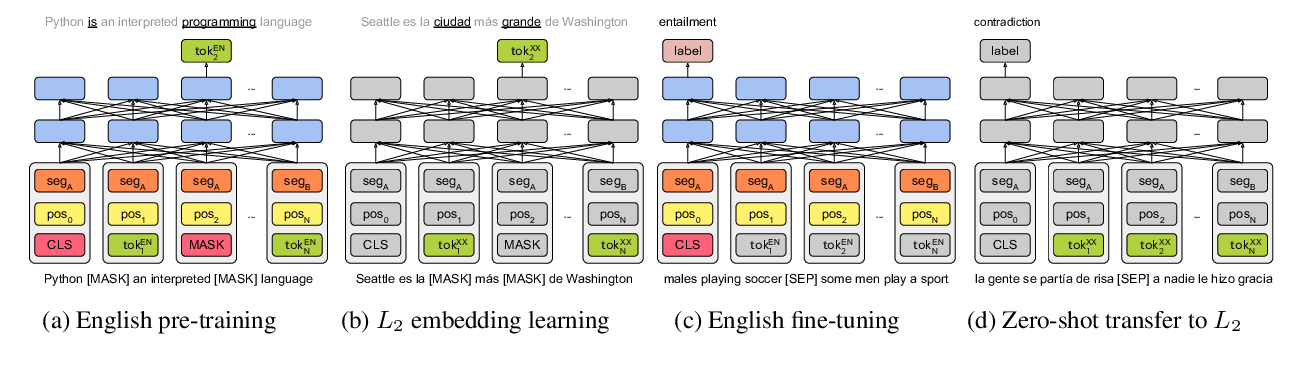
Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer
Jieyu Zhao, Subhabrata Mukherjee, Saghar Hosseini, Kai-Wei Chang, Ahmed Hassan Awadallah,
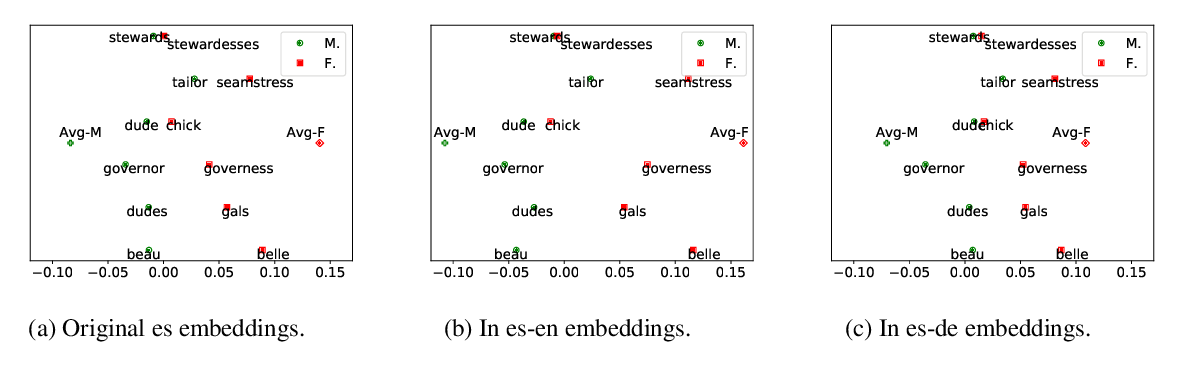
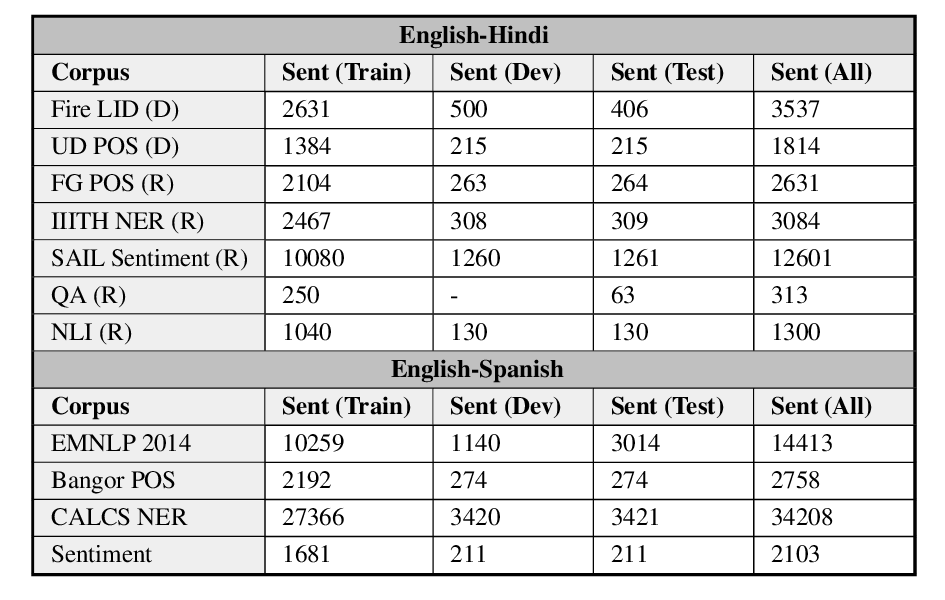
GLUECoS: An Evaluation Benchmark for Code-Switched NLP
Simran Khanuja, Sandipan Dandapat, Anirudh Srinivasan, Sunayana Sitaram, Monojit Choudhury,
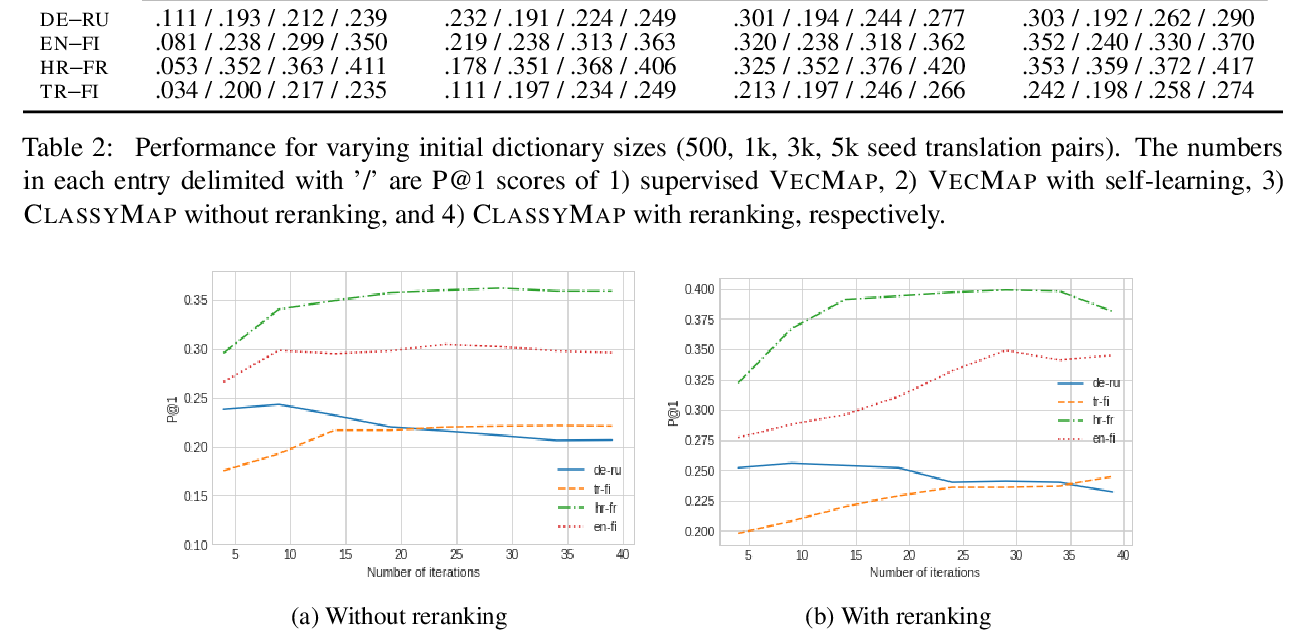
Classification-Based Self-Learning for Weakly Supervised Bilingual Lexicon Induction
Mladen Karan, Ivan Vulić, Anna Korhonen, Goran Glavaš,