Building a Japanese Typo Dataset from Wikipedia's Revision History
Yu Tanaka, Yugo Murawaki, Daisuke Kawahara, Sadao Kurohashi
Student Research Workshop SRW Paper
Session 6B: Jul 7
(06:00-07:00 GMT)

Session 7B: Jul 7
(09:00-10:00 GMT)
Abstract:
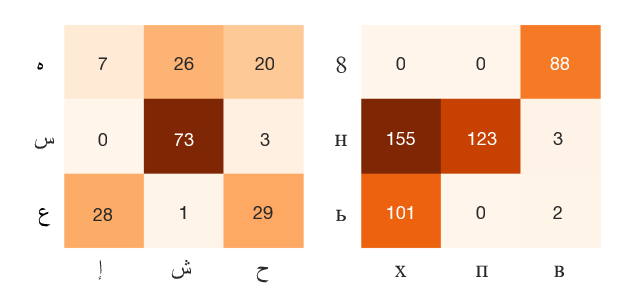
User generated texts contain many typos for which correction is necessary for NLP systems to work. Although a large number of typo–correction pairs are needed to develop a data-driven typo correction system, no such dataset is available for Japanese. In this paper, we extract over half a million Japanese typo–correction pairs from Wikipedia’s revision history. Unlike other languages, Japanese poses unique challenges: (1) Japanese texts are unsegmented so that we cannot simply apply a spelling checker, and (2) the way people inputting kanji logographs results in typos with drastically different surface forms from correct ones. We address them by combining character-based extraction rules, morphological analyzers to guess readings, and various filtering methods. We evaluate the dataset using crowdsourcing and run a baseline seq2seq model for typo correction.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Speak to your Parser: Interactive Text-to-SQL with Natural Language Feedback
Ahmed Elgohary, Saghar Hosseini, Ahmed Hassan Awadallah,
Supervised Grapheme-to-Phoneme Conversion of Orthographic Schwas in Hindi and Punjabi
Aryaman Arora, Luke Gessler, Nathan Schneider,
Phonetic and Visual Priors for Decipherment of Informal Romanization
Maria Ryskina, Matthew R. Gormley, Taylor Berg-Kirkpatrick,