Phonetic and Visual Priors for Decipherment of Informal Romanization
Maria Ryskina, Matthew R. Gormley, Taylor Berg-Kirkpatrick
Phonology, Morphology and Word Segmentation Long Paper
Session 14A: Jul 8
(17:00-18:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
Informal romanization is an idiosyncratic process used by humans in informal digital communication to encode non-Latin script languages into Latin character sets found on common keyboards. Character substitution choices differ between users but have been shown to be governed by the same main principles observed across a variety of languages---namely, character pairs are often associated through phonetic or visual similarity. We propose a noisy-channel WFST cascade model for deciphering the original non-Latin script from observed romanized text in an unsupervised fashion. We train our model directly on romanized data from two languages: Egyptian Arabic and Russian. We demonstrate that adding inductive bias through phonetic and visual priors on character mappings substantially improves the model's performance on both languages, yielding results much closer to the supervised skyline. Finally, we introduce a new dataset of romanized Russian, collected from a Russian social network website and partially annotated for our experiments.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
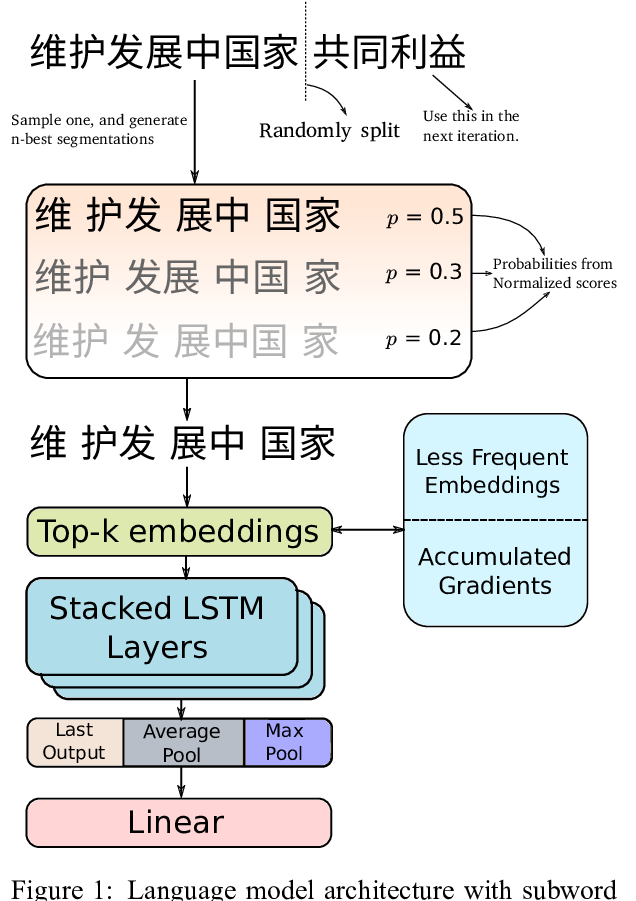
Joint Diacritization, Lemmatization, Normalization, and Fine-Grained Morphological Tagging
Nasser Zalmout, Nizar Habash,
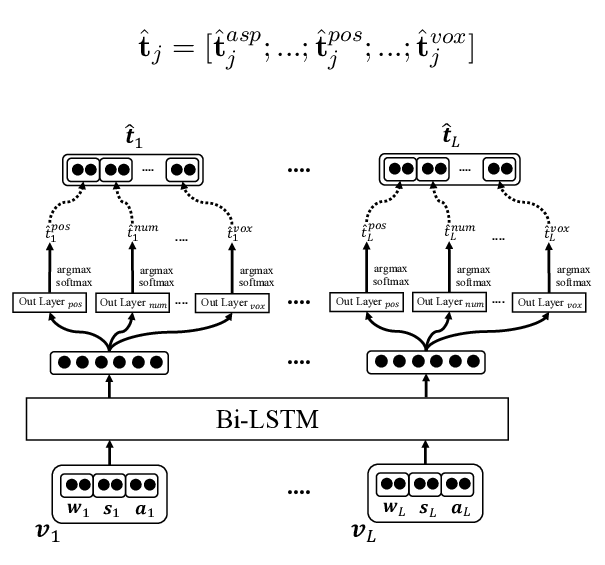
NAT: Noise-Aware Training for Robust Neural Sequence Labeling
Marcin Namysl, Sven Behnke, Joachim Köhler,
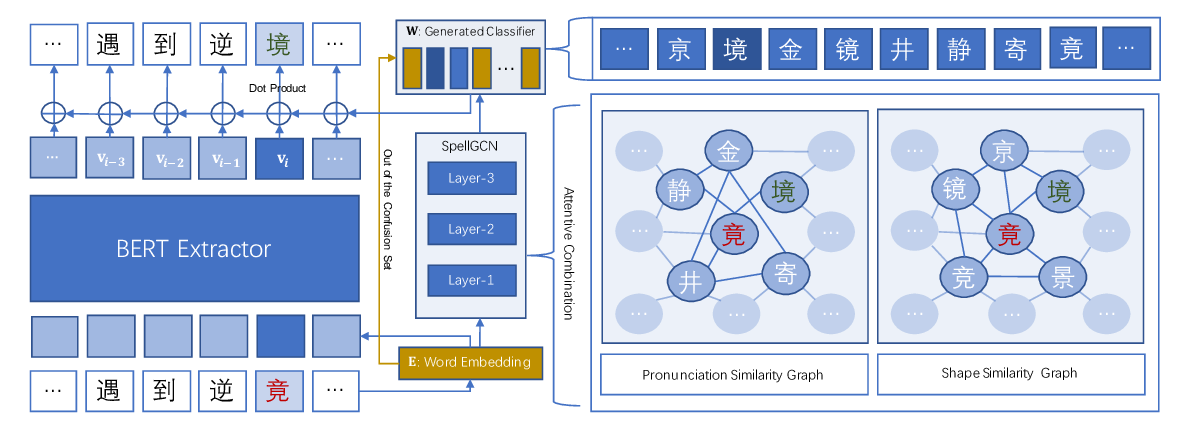
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
Xingyi Cheng, Weidi Xu, Kunlong Chen, Shaohua Jiang, Feng Wang, Taifeng Wang, Wei Chu, Yuan Qi,