Paraphrase-Sense-Tagged Sentences
Anne Cocos, Chris Callison-Burch
Resources and Evaluation TACL Paper
Session 8B: Jul 7
(13:00-14:00 GMT)

Session 10A: Jul 7
(20:00-21:00 GMT)
Abstract:
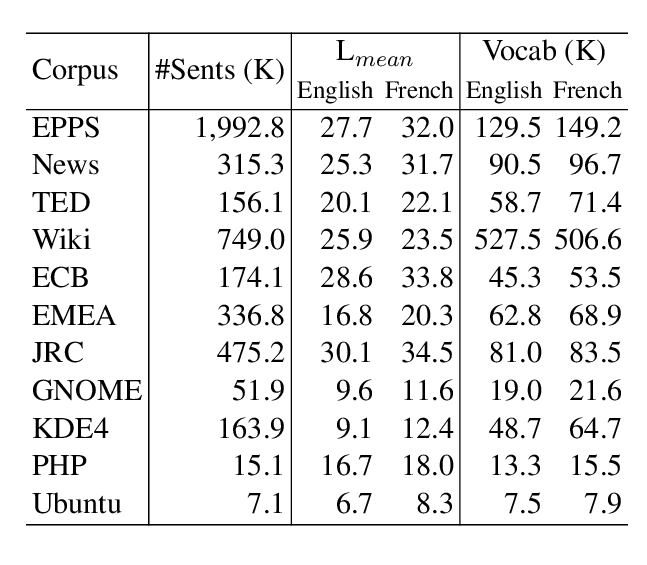
Many natural language processing tasks require discriminating the particular meaning of a word in context, but building corpora for developing sense-aware models can be a challenge. We present a large resource of example usages for words having a particular meaning, called Paraphrase-Sense-Tagged Sentences (PSTS). Built upon the premise that a word's paraphrases instantiate its fine-grained meanings -- i.e. 'bug' has different meanings corresponding to its paraphrases 'fly' and 'microbe' -- the resource contains up to 10,000 sentences for each of 3 million target-paraphrase pairs where the target word takes on the meaning of the paraphrase. We describe an automatic method based on bilingual pivoting used to enumerate sentences for PSTS, and present two models for ranking PSTS sentences based on their quality. Finally, we demonstrate the utility of PSTS by using it to build a dataset for the task of hypernym prediction in context. Training a model on this automatically-generated dataset produces accuracy that is competitive with a model trained on smaller datasets crafted with some manual effort.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data
Emily M. Bender, Alexander Koller,

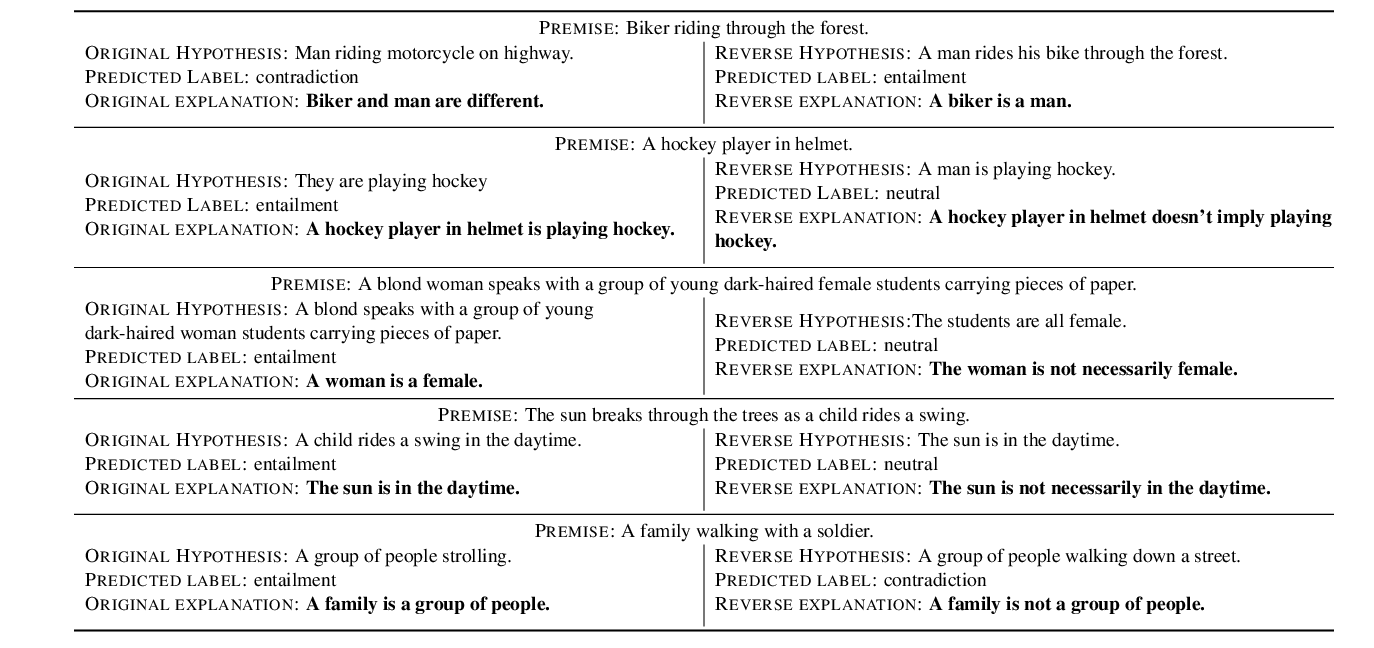
Make Up Your Mind! Adversarial Generation of Inconsistent Natural Language Explanations
Oana-Maria Camburu, Brendan Shillingford, Pasquale Minervini, Thomas Lukasiewicz, Phil Blunsom,
Boosting Neural Machine Translation with Similar Translations
Jitao XU, Josep Crego, Jean Senellart,