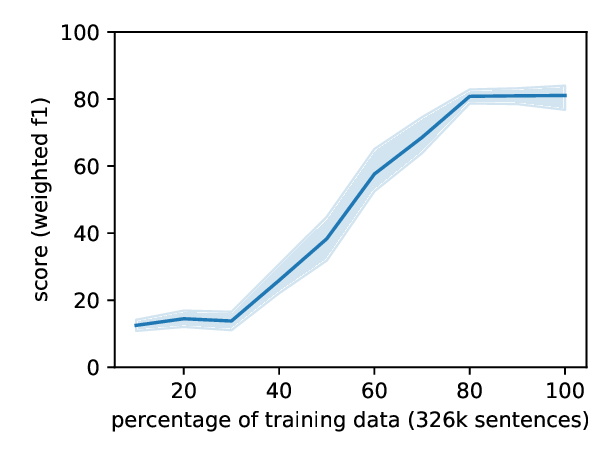
Code and Named Entity Recognition in StackOverflow
Jeniya Tabassum, Mounica Maddela, Wei Xu, Alan Ritter
Resources and Evaluation Long Paper
Session 9A: Jul 7
(17:00-18:00 GMT)

Session 10A: Jul 7
(20:00-21:00 GMT)
Abstract:
There is an increasing interest in studying natural language and computer code together, as large corpora of programming texts become readily available on the Internet. For example, StackOverflow currently has over 15 million programming related questions written by 8.5 million users. Meanwhile, there is still a lack of fundamental NLP techniques for identifying code tokens or software-related named entities that appear within natural language sentences. In this paper, we introduce a new named entity recognition (NER) corpus for the computer programming domain, consisting of 15,372 sentences annotated with 20 fine-grained entity types. We also present the SoftNER model that combines contextual information with domain specific knowledge using an attention network. The code token recognizer combined with an entity segmentation model we proposed, consistently improves the performance of the named entity tagger. Our proposed SoftNER tagger outperforms the BiLSTM-CRF model with an absolute increase of +9.73 F-1 score on StackOverflow data. We have published our code and data at: https://github.com/jeniyat/StackOverflowNER
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Incorporating External Knowledge through Pre-training for Natural Language to Code Generation
Frank F. Xu, Zhengbao Jiang, Pengcheng Yin, Bogdan Vasilescu, Graham Neubig,

A Transformer-based Approach for Source Code Summarization
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang,

Stanza: A Python Natural Language Processing Toolkit for Many Human Languages
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, Christopher D. Manning,