Multilingual Universal Sentence Encoder for Semantic Retrieval
Yinfei Yang, Daniel Cer, Amin Ahmad, Mandy Guo, Jax Law, Noah Constant, Gustavo Hernandez Abrego, Steve Yuan, Chris Tar, Yun-hsuan Sung, Brian Strope, Ray Kurzweil
System Demonstrations Demo Paper
Demo Session 4A-1: Jul 6
(17:00-18:00 GMT)

Demo Session 5B-1: Jul 6
(20:45-21:45 GMT)
Abstract:
We present easy-to-use retrieval focused multilingual sentence embedding models, made available on TensorFlow Hub. The models embed text from 16 languages into a shared semantic space using a multi-task trained dual-encoder that learns tied cross-lingual representations via translation bridge tasks (Chidambaram et al., 2018). The models achieve a new state-of-the-art in performance on monolingual and cross-lingual semantic retrieval (SR). Competitive performance is obtained on the related tasks of translation pair bitext retrieval (BR) and retrieval question answering (ReQA). On transfer learning tasks, our multilingual embeddings approach, and in some cases exceed, the performance of English only sentence embeddings.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
A Monolingual Approach to Contextualized Word Embeddings for Mid-Resource Languages
Pedro Javier Ortiz Suárez, Laurent Romary, Benoît Sagot,
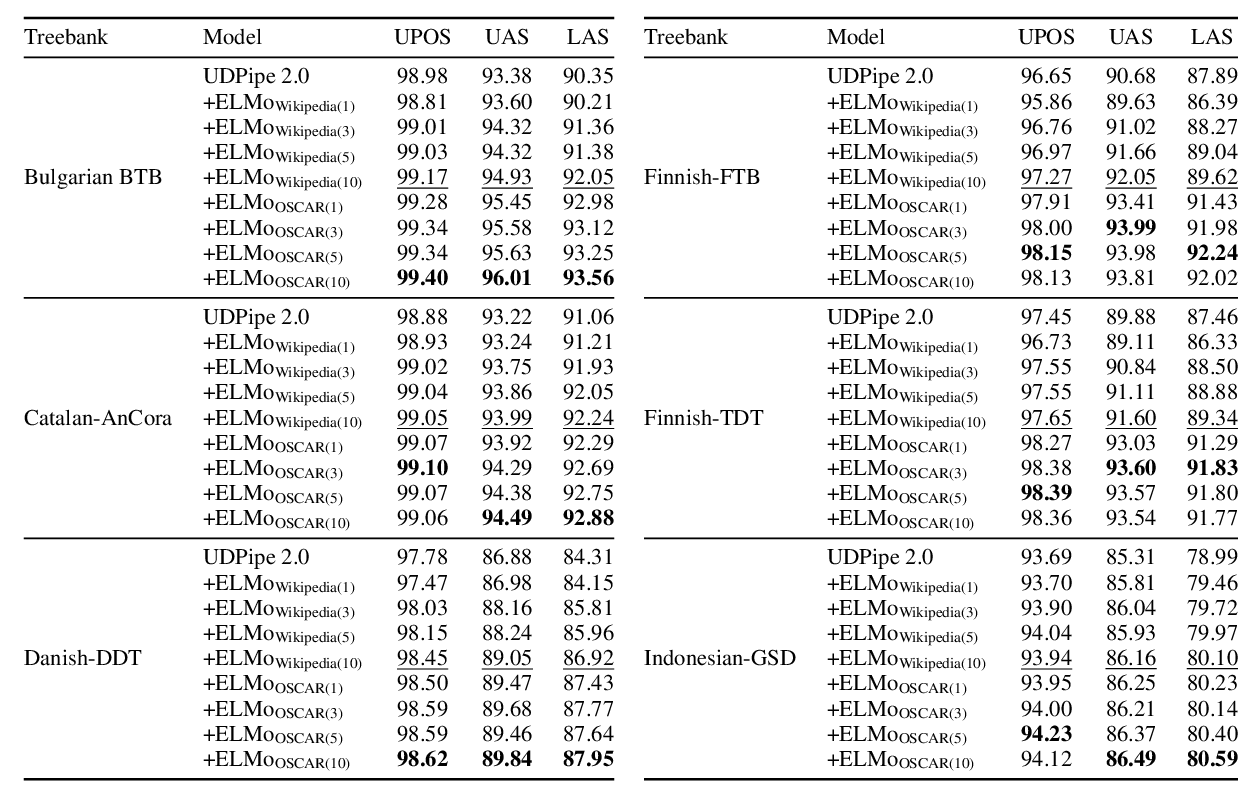
On the Cross-lingual Transferability of Monolingual Representations
Mikel Artetxe, Sebastian Ruder, Dani Yogatama,
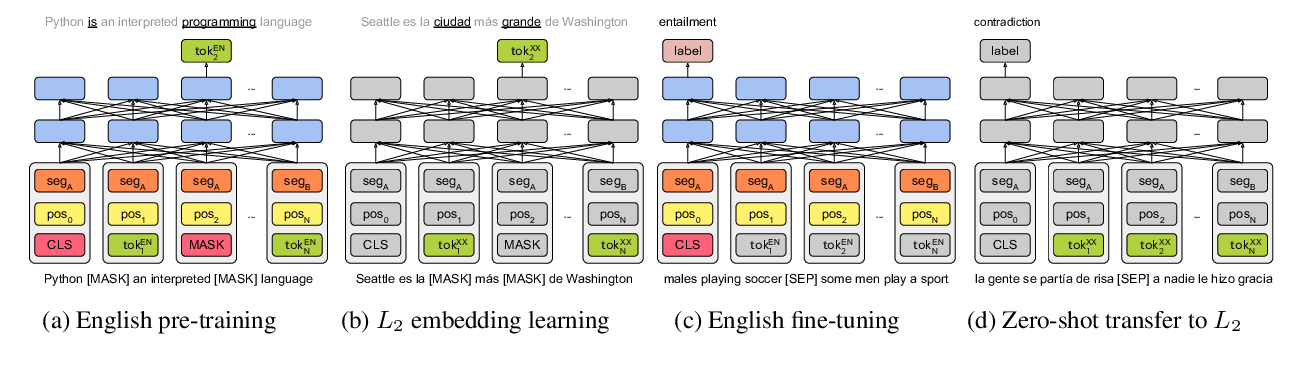
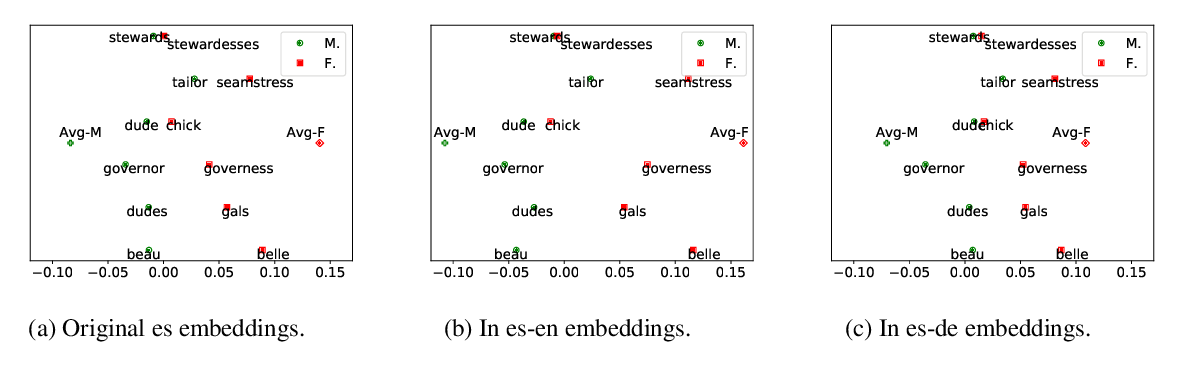
Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer
Jieyu Zhao, Subhabrata Mukherjee, Saghar Hosseini, Kai-Wei Chang, Ahmed Hassan Awadallah,
GLUECoS: An Evaluation Benchmark for Code-Switched NLP
Simran Khanuja, Sandipan Dandapat, Anirudh Srinivasan, Sunayana Sitaram, Monojit Choudhury,