A Monolingual Approach to Contextualized Word Embeddings for Mid-Resource Languages
Pedro Javier Ortiz Suárez, Laurent Romary, Benoît Sagot
Resources and Evaluation Long Paper
Session 2B: Jul 6
(09:00-10:00 GMT)

Session 3A: Jul 6
(12:00-13:00 GMT)
Abstract:
We use the multilingual OSCAR corpus, extracted from Common Crawl via language classification, filtering and cleaning, to train monolingual contextualized word embeddings (ELMo) for several mid-resource languages. We then compare the performance of OSCAR-based and Wikipedia-based ELMo embeddings for these languages on the part-of-speech tagging and parsing tasks. We show that, despite the noise in the Common-Crawl-based OSCAR data, embeddings trained on OSCAR perform much better than monolingual embeddings trained on Wikipedia. They actually equal or improve the current state of the art in tagging and parsing for all five languages. In particular, they also improve over multilingual Wikipedia-based contextual embeddings (multilingual BERT), which almost always constitutes the previous state of the art, thereby showing that the benefit of a larger, more diverse corpus surpasses the cross-lingual benefit of multilingual embedding architectures.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
On the Cross-lingual Transferability of Monolingual Representations
Mikel Artetxe, Sebastian Ruder, Dani Yogatama,
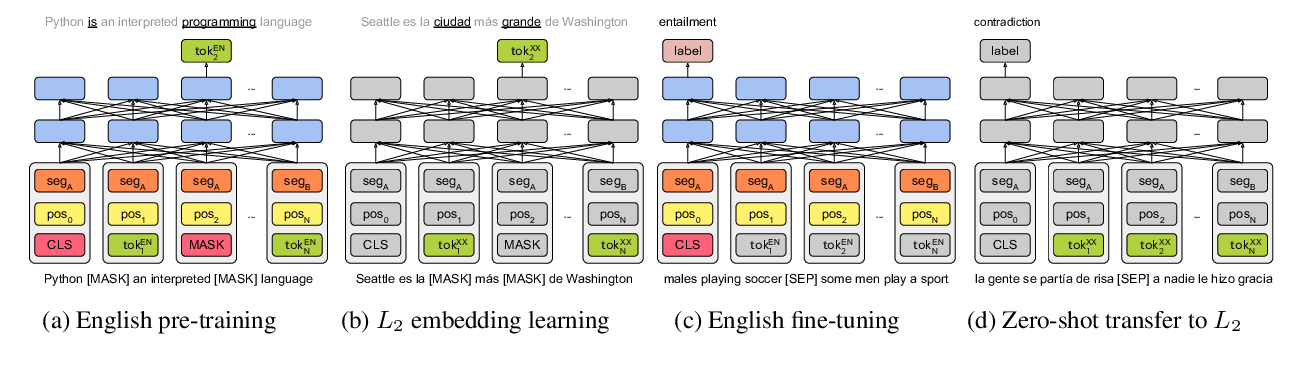
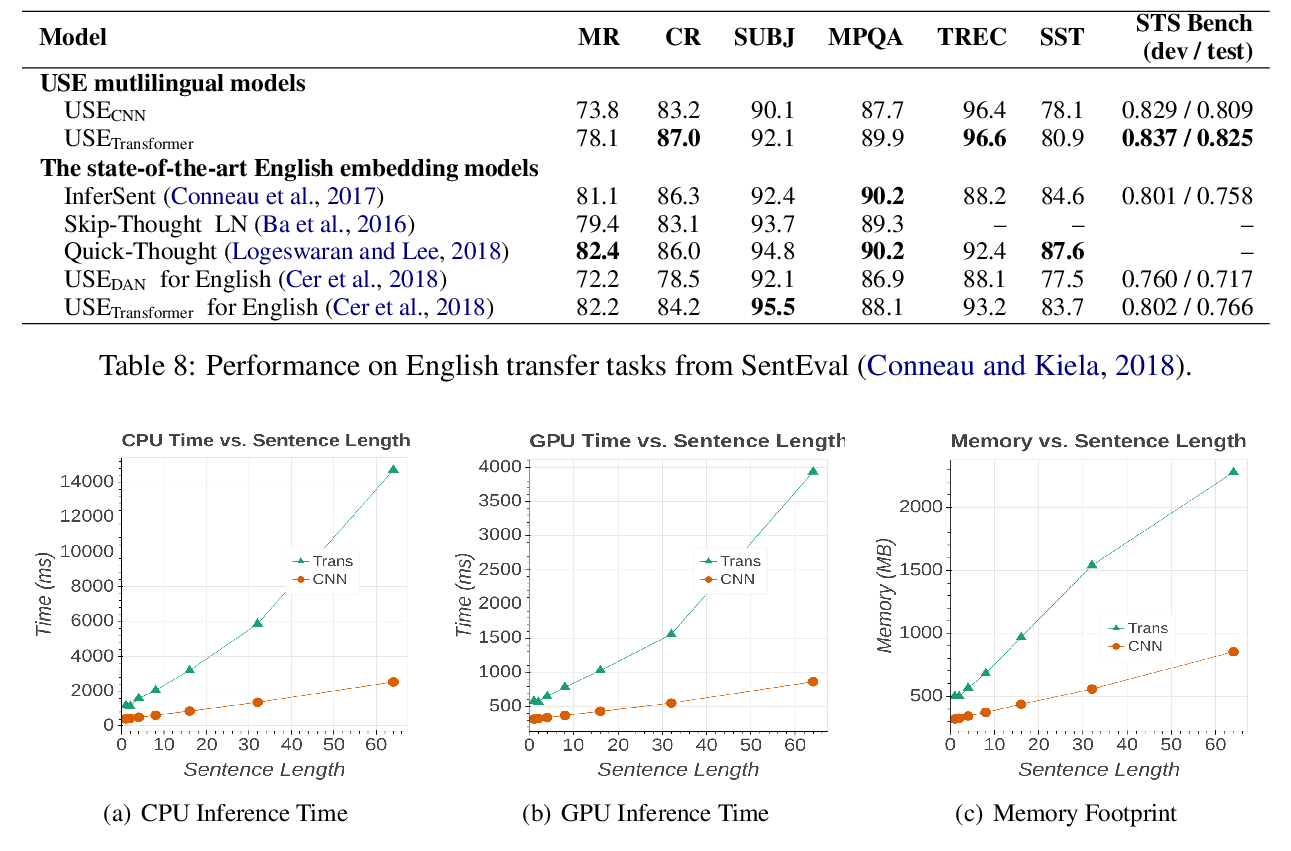
Multilingual Universal Sentence Encoder for Semantic Retrieval
Yinfei Yang, Daniel Cer, Amin Ahmad, Mandy Guo, Jax Law, Noah Constant, Gustavo Hernandez Abrego, Steve Yuan, Chris Tar, Yun-hsuan Sung, Brian Strope, Ray Kurzweil,
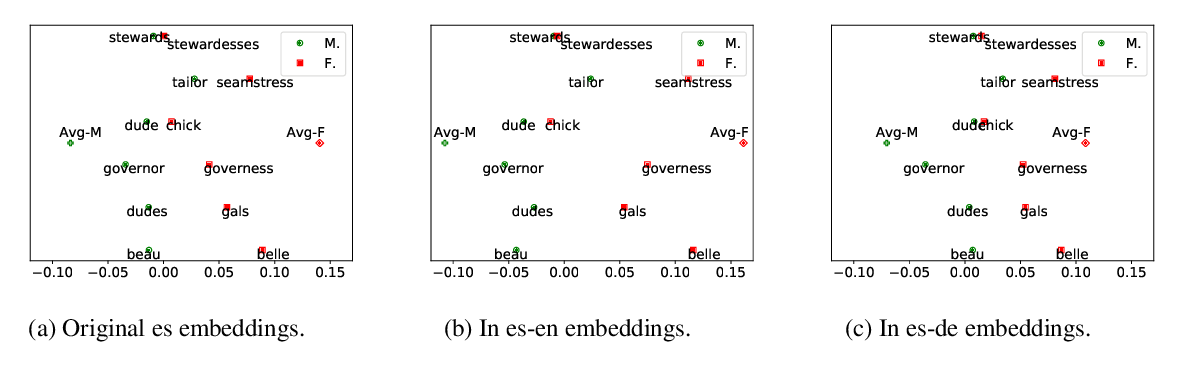
Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer
Jieyu Zhao, Subhabrata Mukherjee, Saghar Hosseini, Kai-Wei Chang, Ahmed Hassan Awadallah,
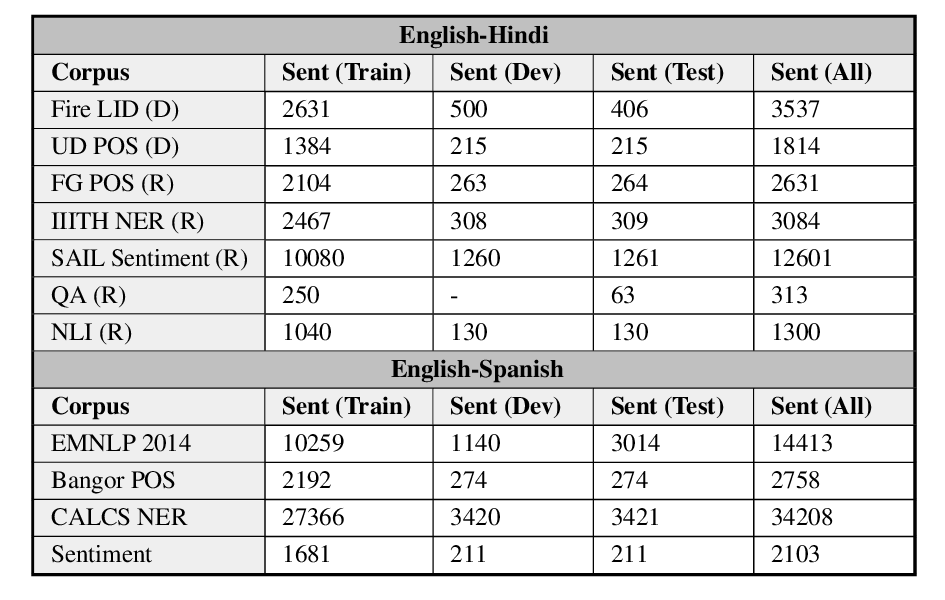
GLUECoS: An Evaluation Benchmark for Code-Switched NLP
Simran Khanuja, Sandipan Dandapat, Anirudh Srinivasan, Sunayana Sitaram, Monojit Choudhury,