OpusFilter: A Configurable Parallel Corpus Filtering Toolbox
Mikko Aulamo, Sami Virpioja, Jörg Tiedemann
System Demonstrations Demo Paper
Demo Session 2A-2: Jul 7
(08:00-09:00 GMT)

Demo Session 4A-2: Jul 7
(17:00-18:00 GMT)
Abstract:
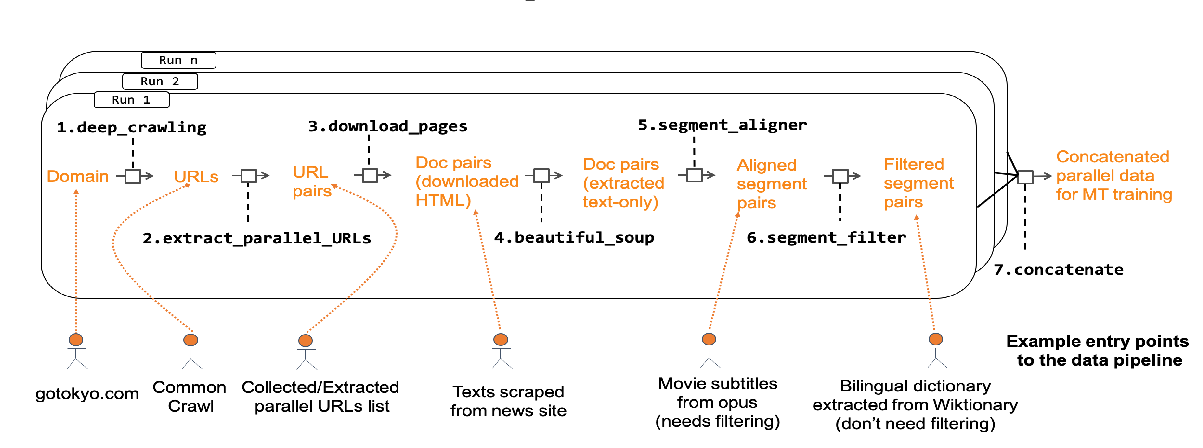
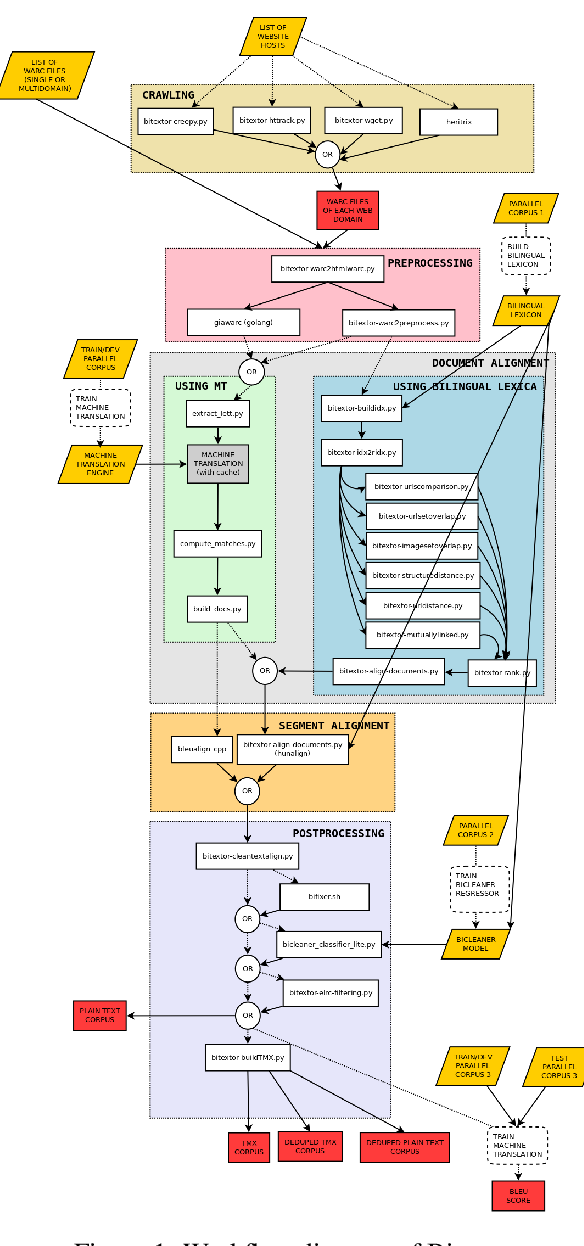
This paper introduces OpusFilter, a flexible and modular toolbox for filtering parallel corpora. It implements a number of components based on heuristic filters, language identification libraries, character-based language models, and word alignment tools, and it can easily be extended with custom filters. Bitext segments can be ranked according to their quality or domain match using single features or a logistic regression model that can be trained without manually labeled training data. We demonstrate the effectiveness of OpusFilter on the example of a Finnish-English news translation task based on noisy web-crawled training data. Applying our tool leads to improved translation quality while significantly reducing the size of the training data, also clearly outperforming an alternative ranking given in the crawled data set. Furthermore, we show the ability of OpusFilter to perform data selection for domain adaptation.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
ParaCrawl: Web-Scale Acquisition of Parallel Corpora
Marta Bañón, Pinzhen Chen, Barry Haddow, Kenneth Heafield, Hieu Hoang, Miquel Esplà-Gomis, Mikel L. Forcada, Amir Kamran, Faheem Kirefu, Philipp Koehn, Sergio Ortiz Rojas, Leopoldo Pla Sempere, Gema Ramírez-Sánchez, Elsa Sarrías, Marek Strelec, Brian Thompson, William Waites, Dion Wiggins, Jaume Zaragoza,
Effectively Aligning and Filtering Parallel Corpora under Sparse Data Conditions
Steinþór Steingrímsson, Hrafn Loftsson, Andy Way,

To Pretrain or Not to Pretrain: Examining the Benefits of Pretrainng on Resource Rich Tasks
Sinong Wang, Madian Khabsa, Hao Ma,