Parallel Corpus Filtering via Pre-trained Language Models
Boliang Zhang, Ajay Nagesh, Kevin Knight
Machine Translation Long Paper
Session 14B: Jul 8
(18:00-19:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
Web-crawled data provides a good source of parallel corpora for training machine translation models. It is automatically obtained, but extremely noisy, and recent work shows that neural machine translation systems are more sensitive to noise than traditional statistical machine translation methods. In this paper, we propose a novel approach to filter out noisy sentence pairs from web-crawled corpora via pre-trained language models. We measure sentence parallelism by leveraging the multilingual capability of BERT and use the Generative Pre-training (GPT) language model as a domain filter to balance data domains. We evaluate the proposed method on the WMT 2018 Parallel Corpus Filtering shared task, and on our own web-crawled Japanese-Chinese parallel corpus. Our method significantly outperforms baselines and achieves a new state-of-the-art. In an unsupervised setting, our method achieves comparable performance to the top-1 supervised method. We also evaluate on a web-crawled Japanese-Chinese parallel corpus that we make publicly available.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
ParaCrawl: Web-Scale Acquisition of Parallel Corpora
Marta Bañón, Pinzhen Chen, Barry Haddow, Kenneth Heafield, Hieu Hoang, Miquel Esplà-Gomis, Mikel L. Forcada, Amir Kamran, Faheem Kirefu, Philipp Koehn, Sergio Ortiz Rojas, Leopoldo Pla Sempere, Gema Ramírez-Sánchez, Elsa Sarrías, Marek Strelec, Brian Thompson, William Waites, Dion Wiggins, Jaume Zaragoza,
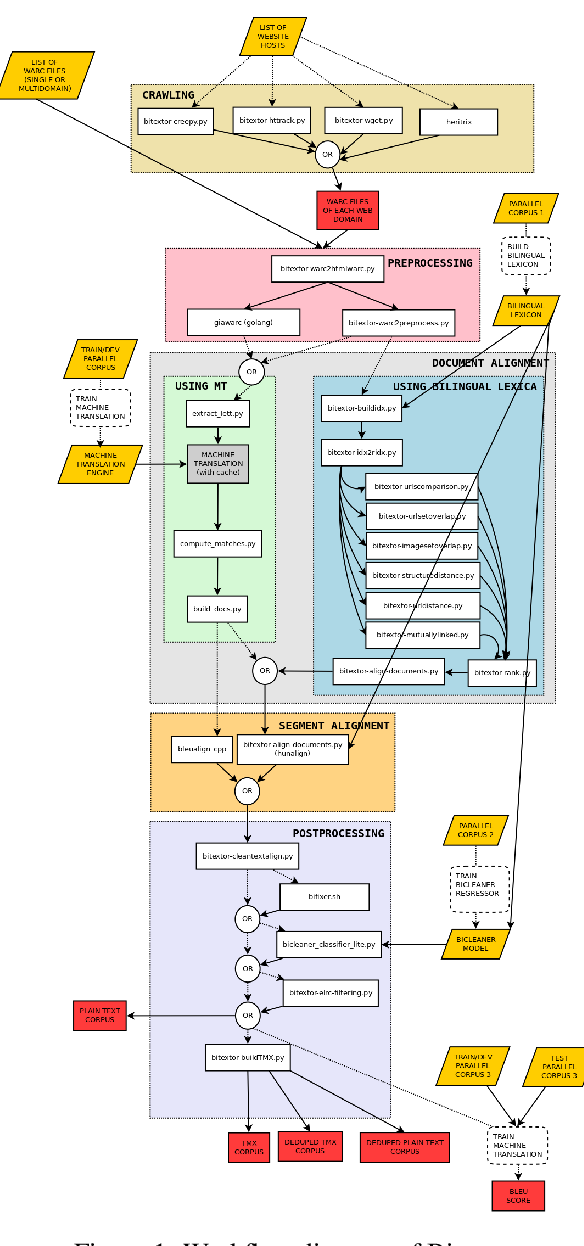
OpusFilter: A Configurable Parallel Corpus Filtering Toolbox
Mikko Aulamo, Sami Virpioja, Jörg Tiedemann,
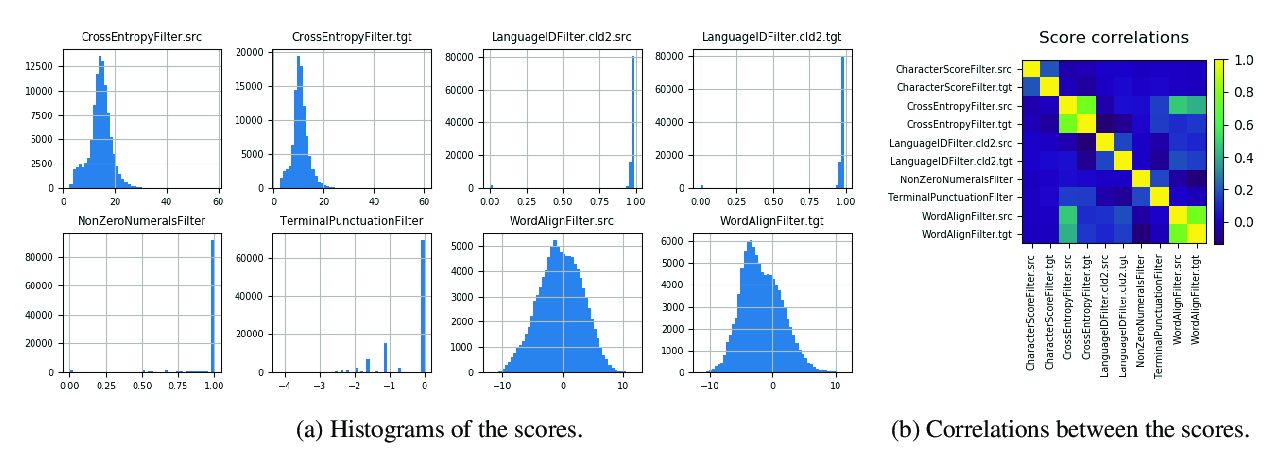
Unsupervised Multilingual Sentence Embeddings for Parallel Corpus Mining
Ivana Kvapilíková, Mikel Artetxe, Gorka Labaka, Eneko Agirre, Ondřej Bojar,