Learning and Evaluating Emotion Lexicons for 91 Languages
Sven Buechel, Susanna Rücker, Udo Hahn
Resources and Evaluation Long Paper
Session 2A: Jul 6
(08:00-09:00 GMT)

Session 3A: Jul 6
(12:00-13:00 GMT)
Abstract:
Emotion lexicons describe the affective meaning of words and thus constitute a centerpiece for advanced sentiment and emotion analysis. Yet, manually curated lexicons are only available for a handful of languages, leaving most languages of the world without such a precious resource for downstream applications. Even worse, their coverage is often limited both in terms of the lexical units they contain and the emotional variables they feature. In order to break this bottleneck, we here introduce a methodology for creating almost arbitrarily large emotion lexicons for any target language. Our approach requires nothing but a source language emotion lexicon, a bilingual word translation model, and a target language embedding model. Fulfilling these requirements for 91 languages, we are able to generate representationally rich high-coverage lexicons comprising eight emotional variables with more than 100k lexical entries each. We evaluated the automatically generated lexicons against human judgment from 26 datasets, spanning 12 typologically diverse languages, and found that our approach produces results in line with state-of-the-art monolingual approaches to lexicon creation and even surpasses human reliability for some languages and variables. Code and data are available at https://github.com/JULIELab/MEmoLon archived under DOI 10.5281/zenodo.3779901.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
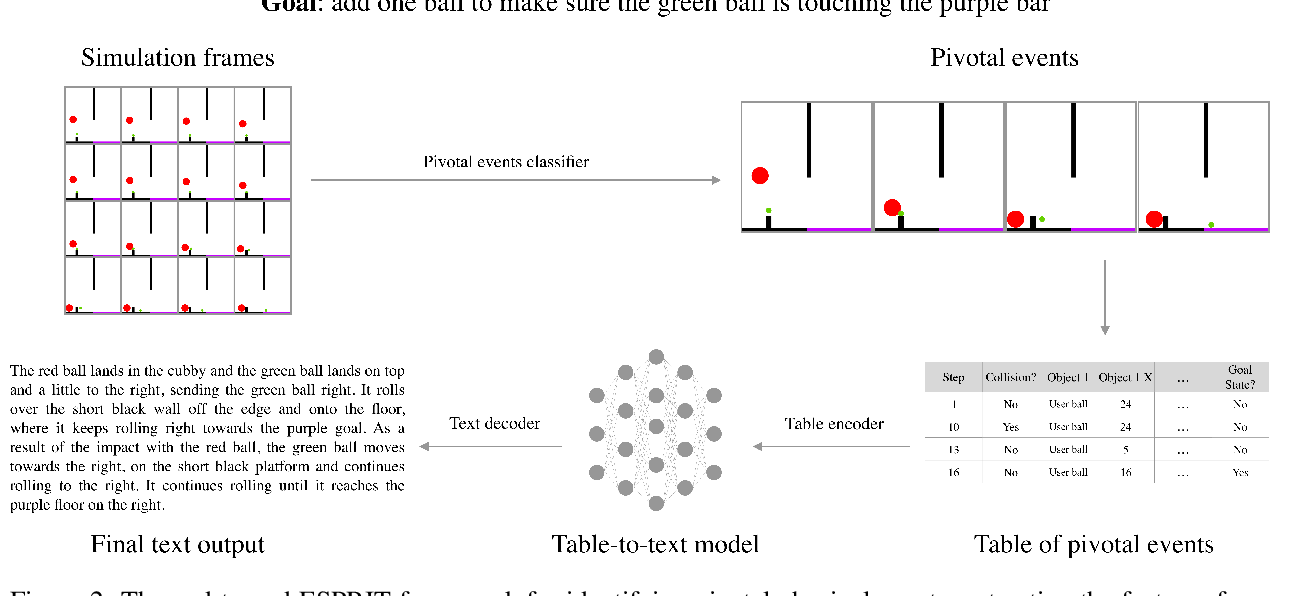
ESPRIT: Explaining Solutions to Physical Reasoning Tasks
Nazneen Fatema Rajani, Rui Zhang, Yi Chern Tan, Stephan Zheng, Jeremy Weiss, Aadit Vyas, Abhijit Gupta, Caiming Xiong, Richard Socher, Dragomir Radev,
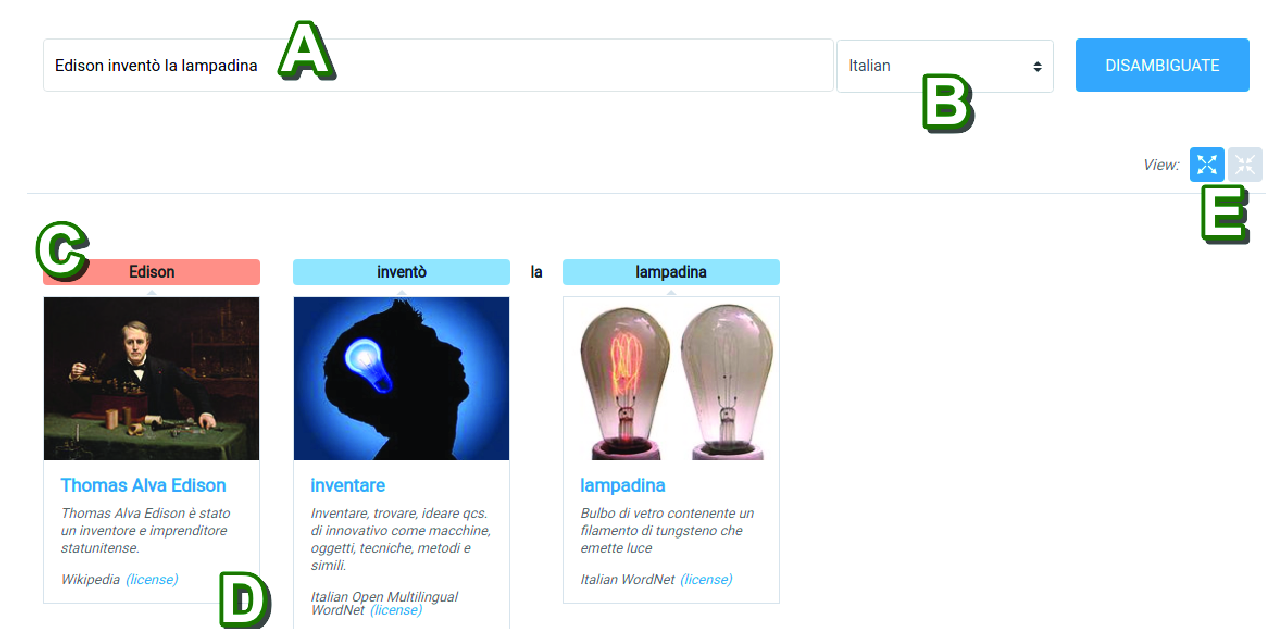
Personalized PageRank with Syntagmatic Information for Multilingual Word Sense Disambiguation
Federico Scozzafava, Marco Maru, Fabrizio Brignone, Giovanni Torrisi, Roberto Navigli,
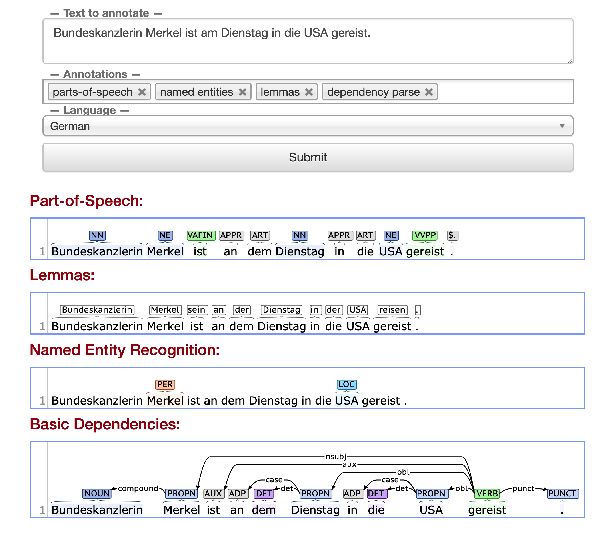
Stanza: A Python Natural Language Processing Toolkit for Many Human Languages
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, Christopher D. Manning,