Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
Sajad Sotudeh Gharebagh, Nazli Goharian, Ross Filice
Summarization Short Paper
Session 3B: Jul 6
(13:00-14:00 GMT)

Session 4B: Jul 6
(18:00-19:00 GMT)
Abstract:
Sequence-to-sequence (seq2seq) network is a well-established model for text summarization task. It can learn to produce readable content; however, it falls short in effectively identifying key regions of the source. In this paper, we approach the content selection problem for clinical abstractive summarization by augmenting salient ontological terms into the summarizer. Our experiments on two publicly available clinical data sets (107,372 reports of MIMIC-CXR, and 3,366 reports of OpenI) show that our model statistically significantly boosts state-of-the-art results in terms of ROUGE metrics (with improvements: 2.9% RG-1, 2.5% RG-2, 1.9% RG-L), in the healthcare domain where any range of improvement impacts patients’ welfare.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
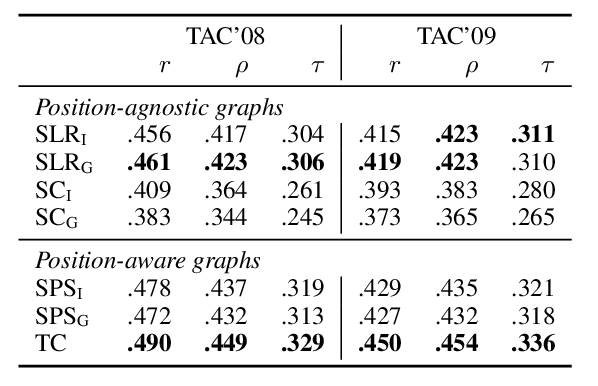
Simple and Effective Retrieve-Edit-Rerank Text Generation
Nabil Hossain, Marjan Ghazvininejad, Luke Zettlemoyer,
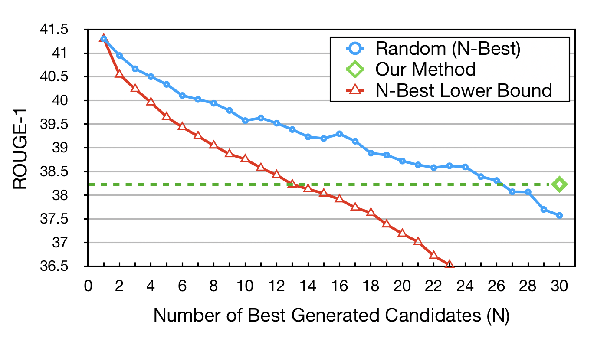
Distilling Knowledge Learned in BERT for Text Generation
Yen-Chun Chen, Zhe Gan, Yu Cheng, Jingzhou Liu, Jingjing Liu,
Multi-Granularity Interaction Network for Extractive and Abstractive Multi-Document Summarization
Hanqi Jin, Tianming Wang, Xiaojun Wan,
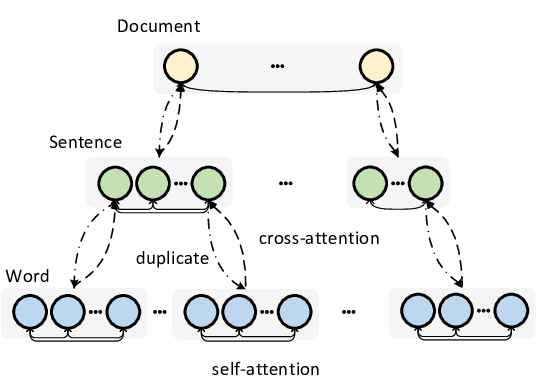
SUPERT: Towards New Frontiers in Unsupervised Evaluation Metrics for Multi-Document Summarization
Yang Gao, Wei Zhao, Steffen Eger,