On Faithfulness and Factuality in Abstractive Summarization
Joshua Maynez, Shashi Narayan, Bernd Bohnet, Ryan McDonald
Summarization Long Paper
Session 3B: Jul 6
(13:00-14:00 GMT)

Session 4B: Jul 6
(18:00-19:00 GMT)
Abstract:
It is well known that the standard likelihood training and approximate decoding objectives in neural text generation models lead to less human-like responses for open-ended tasks such as language modeling and story generation. In this paper we have analyzed limitations of these models for abstractive document summarization and found that these models are highly prone to hallucinate content that is unfaithful to the input document. We conducted a large scale human evaluation of several neural abstractive summarization systems to better understand the types of hallucinations they produce. Our human annotators found substantial amounts of hallucinated content in all model generated summaries. However, our analysis does show that pretrained models are better summarizers not only in terms of raw metrics, i.e., ROUGE, but also in generating faithful and factual summaries as evaluated by humans. Furthermore, we show that textual entailment measures better correlate with faithfulness than standard metrics, potentially leading the way to automatic evaluation metrics as well as training and decoding criteria.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
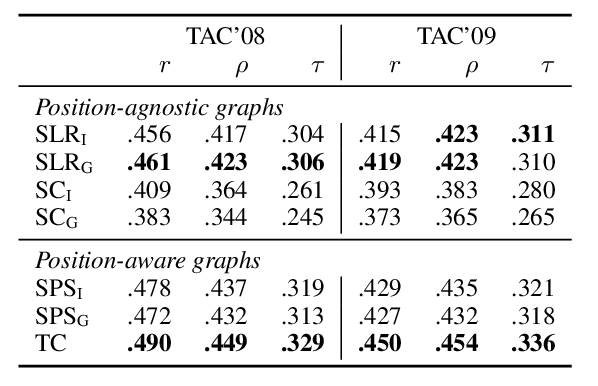
FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization
Esin Durmus, He He, Mona Diab,
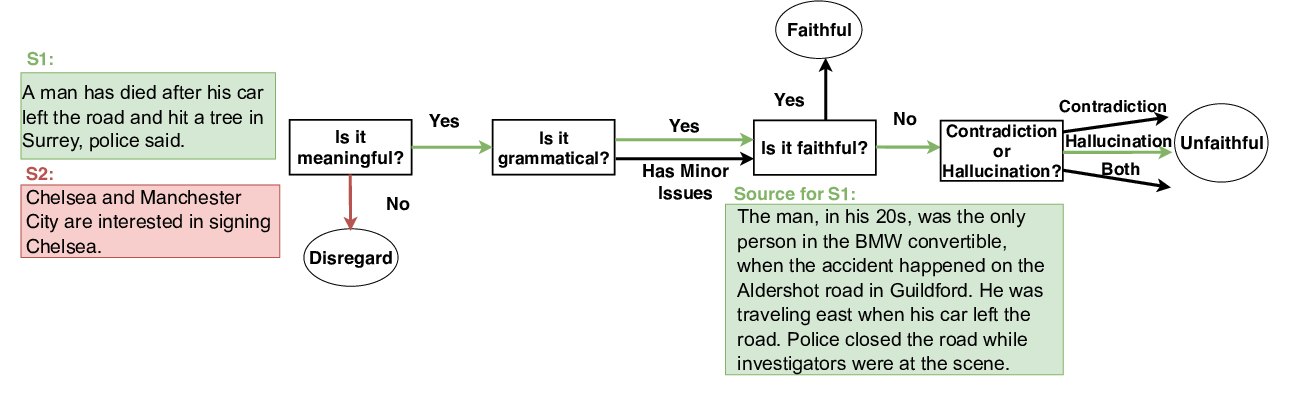
Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward
Luyang Huang, Lingfei Wu, Lu Wang,
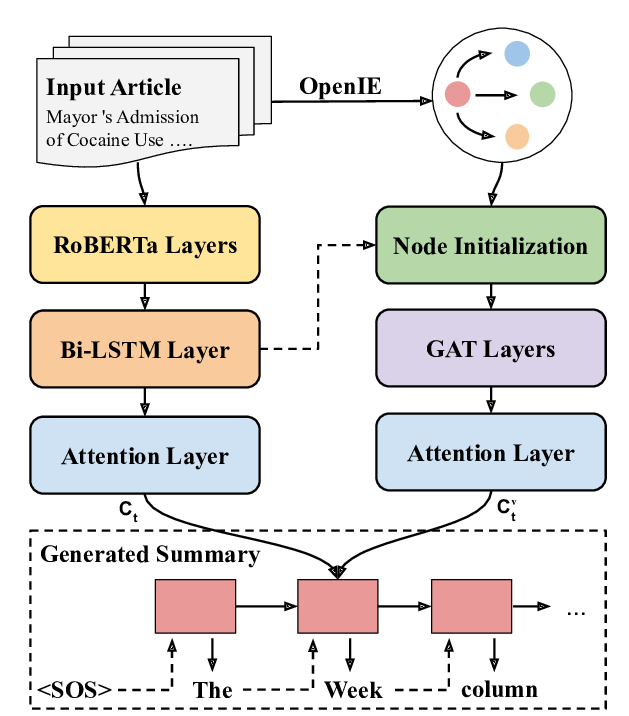
Optimizing the Factual Correctness of a Summary: A Study of Summarizing Radiology Reports
Yuhao Zhang, Derek Merck, Emily Tsai, Christopher D. Manning, Curtis Langlotz,
SUPERT: Towards New Frontiers in Unsupervised Evaluation Metrics for Multi-Document Summarization
Yang Gao, Wei Zhao, Steffen Eger,