Unsupervised Opinion Summarization with Noising and Denoising
Reinald Kim Amplayo, Mirella Lapata
Summarization Long Paper
Session 3B: Jul 6
(13:00-14:00 GMT)

Session 4B: Jul 6
(18:00-19:00 GMT)
Abstract:
The supervised training of high-capacity models on large datasets containing hundreds of thousands of document-summary pairs is critical to the recent success of deep learning techniques for abstractive summarization. Unfortunately, in most domains (other than news) such training data is not available and cannot be easily sourced. In this paper we enable the use of supervised learning for the setting where there are only documents available (e.g., product or business reviews) without ground truth summaries. We create a synthetic dataset from a corpus of user reviews by sampling a review, pretending it is a summary, and generating noisy versions thereof which we treat as pseudo-review input. We introduce several linguistically motivated noise generation functions and a summarization model which learns to denoise the input and generate the original review. At test time, the model accepts genuine reviews and generates a summary containing salient opinions, treating those that do not reach consensus as noise. Extensive automatic and human evaluation shows that our model brings substantial improvements over both abstractive and extractive baselines.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
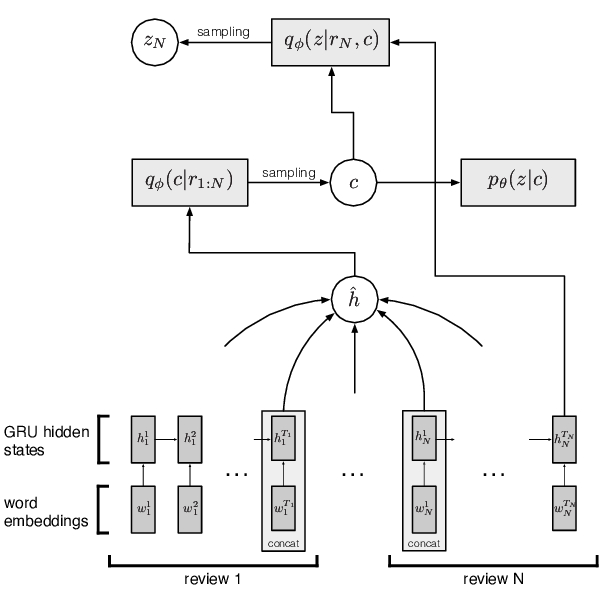
Unsupervised Opinion Summarization as Copycat-Review Generation
Arthur Bražinskas, Mirella Lapata, Ivan Titov,
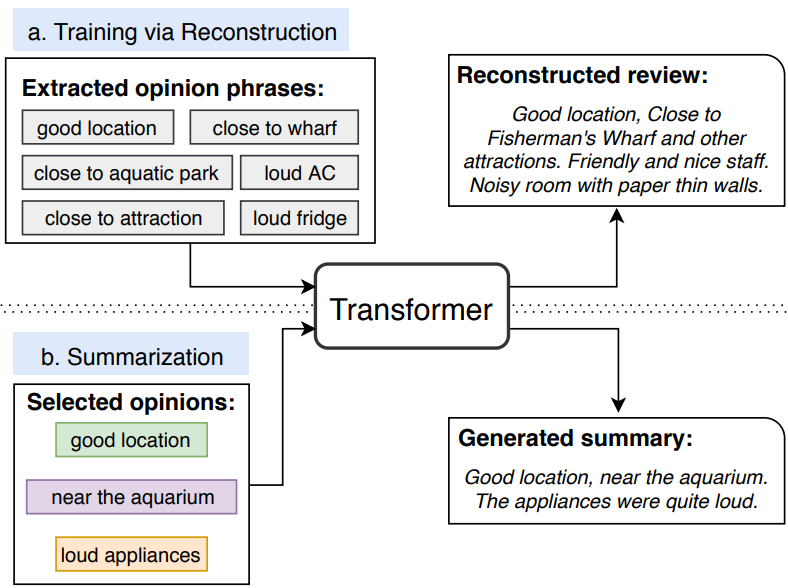
OpinionDigest: A Simple Framework for Opinion Summarization
Yoshihiko Suhara, Xiaolan Wang, Stefanos Angelidis, Wang-Chiew Tan,
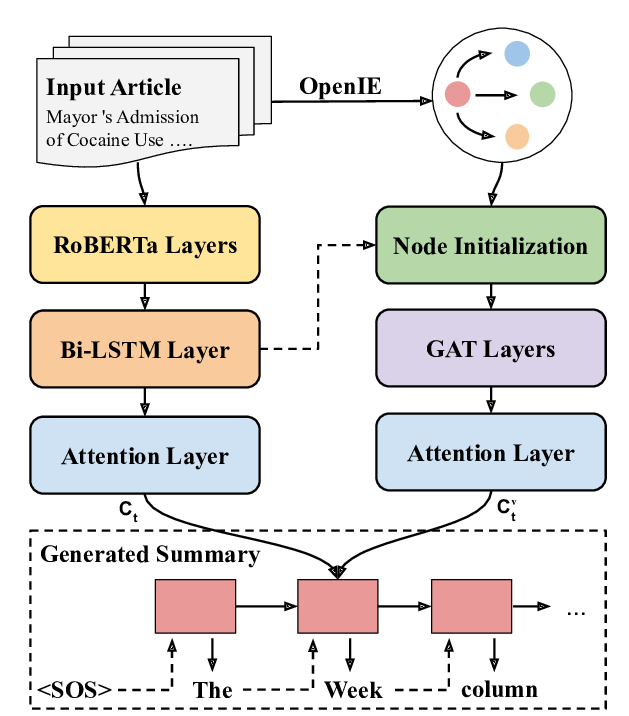
Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward
Luyang Huang, Lingfei Wu, Lu Wang,
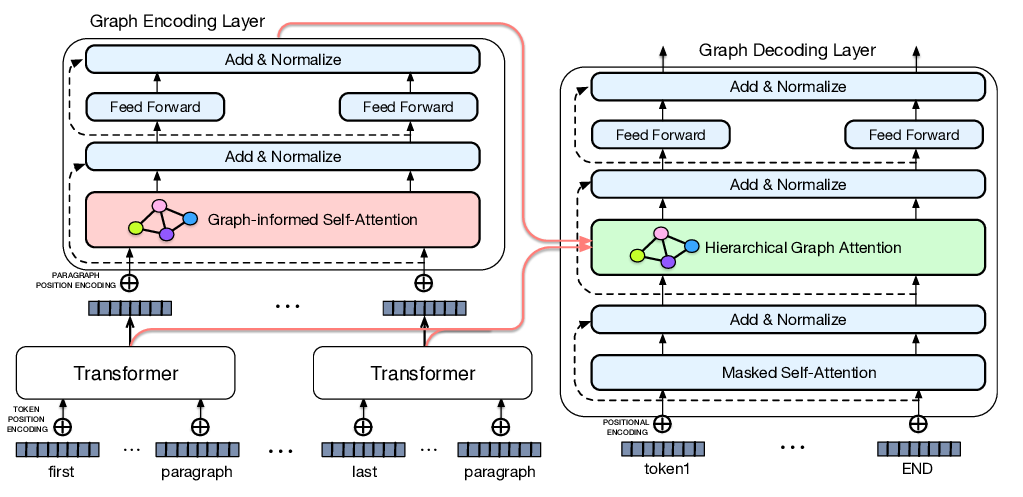
Leveraging Graph to Improve Abstractive Multi-Document Summarization
Wei Li, Xinyan Xiao, Jiachen Liu, Hua Wu, Haifeng Wang, Junping Du,