Span Selection Pre-training for Question Answering
Michael Glass, Alfio Gliozzo, Rishav Chakravarti, Anthony Ferritto, Lin Pan, G P Shrivatsa Bhargav, Dinesh Garg, Avi Sil
Machine Learning for NLP Long Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5B: Jul 6
(21:00-22:00 GMT)
Abstract:
BERT (Bidirectional Encoder Representations from Transformers) and related pre-trained Transformers have provided large gains across many language understanding tasks, achieving a new state-of-the-art (SOTA). BERT is pretrained on two auxiliary tasks: Masked Language Model and Next Sentence Prediction. In this paper we introduce a new pre-training task inspired by reading comprehension to better align the pre-training from memorization to understanding. Span Selection PreTraining (SSPT) poses cloze-like training instances, but rather than draw the answer from the model’s parameters, it is selected from a relevant passage. We find significant and consistent improvements over both BERT-BASE and BERT-LARGE on multiple Machine Reading Comprehension (MRC) datasets. Specifically, our proposed model has strong empirical evidence as it obtains SOTA results on Natural Questions, a new benchmark MRC dataset, outperforming BERT-LARGE by 3 F1 points on short answer prediction. We also show significant impact in HotpotQA, improving answer prediction F1 by 4 points and supporting fact prediction F1 by 1 point and outperforming the previous best system. Moreover, we show that our pre-training approach is particularly effective when training data is limited, improving the learning curve by a large amount.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
SpanBERT: Improving Pre-training by Representing and Predicting Spans
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, Omer Levy,
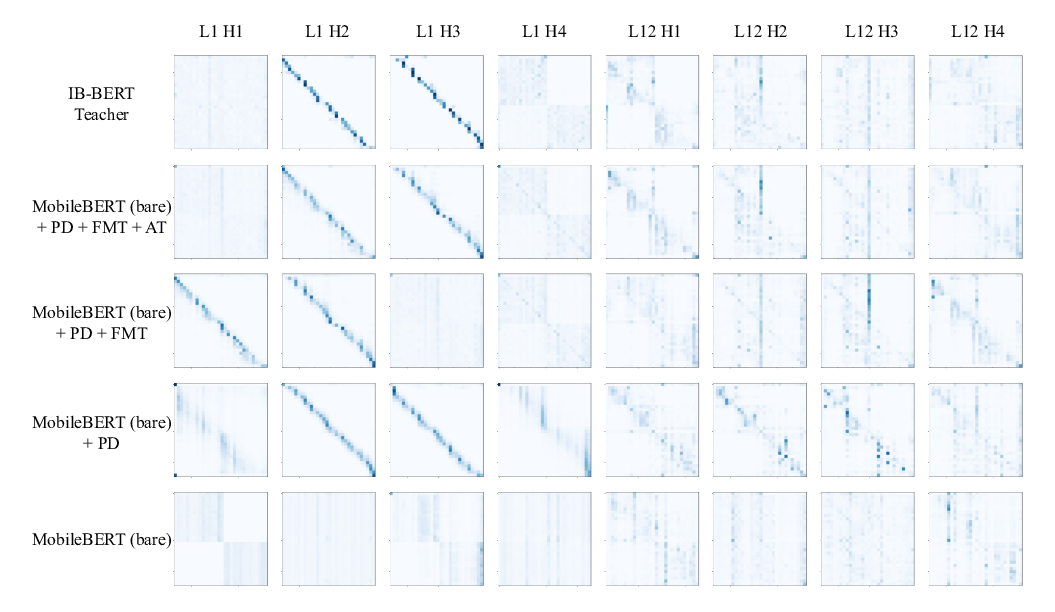
Distilling Knowledge Learned in BERT for Text Generation
Yen-Chun Chen, Zhe Gan, Yu Cheng, Jingzhou Liu, Jingjing Liu,
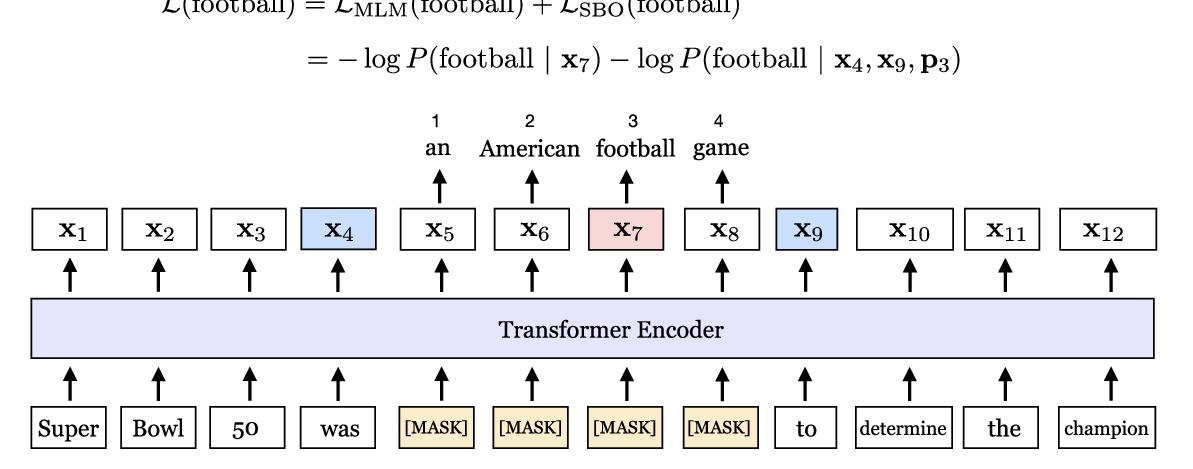
Leveraging Pre-trained Checkpoints for Sequence Generation Tasks
Sascha Rothe, Shashi Narayan and Aliaksei Severyn,
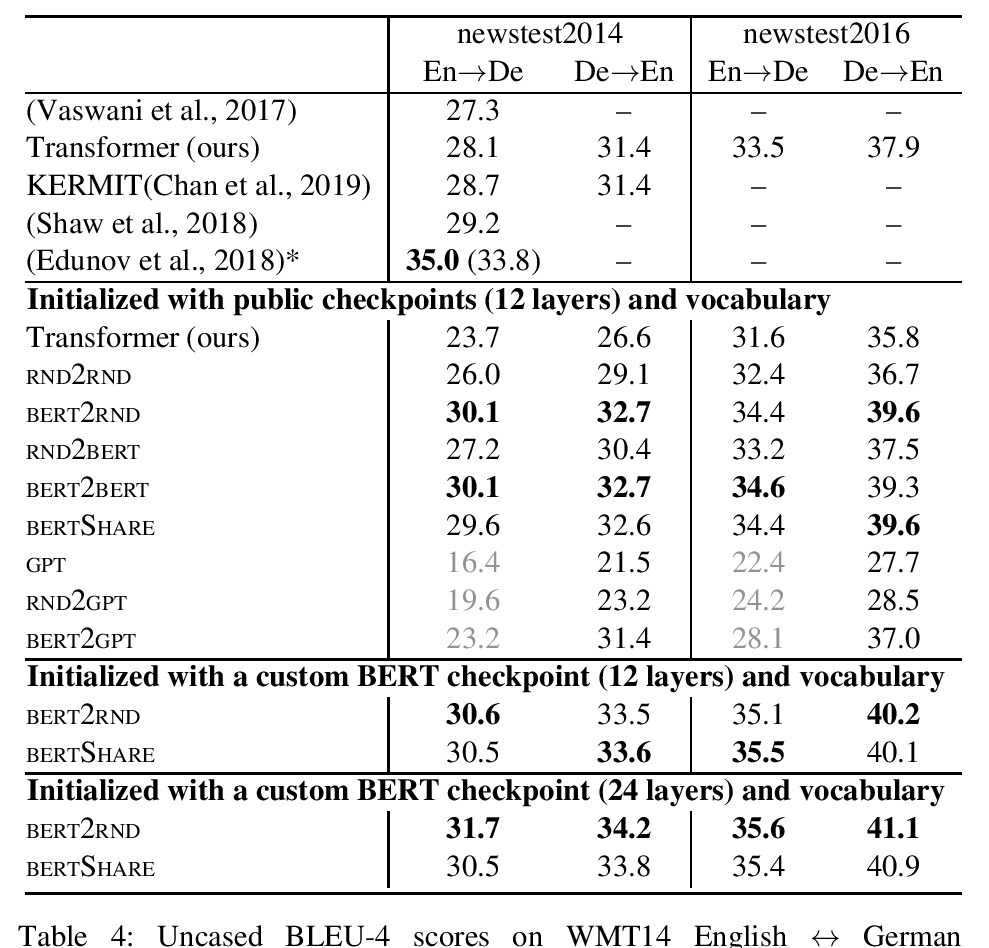
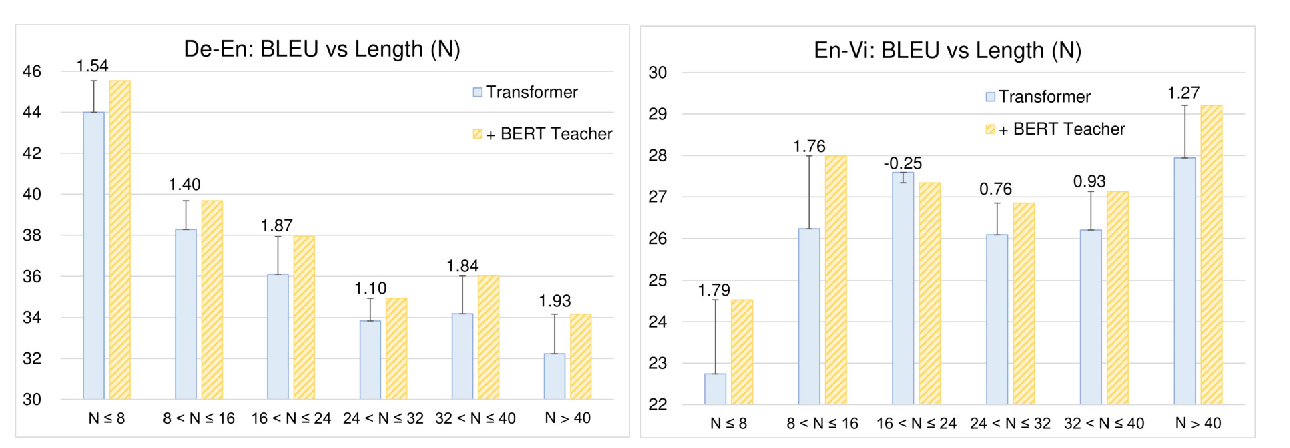
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou,