schuBERT: Optimizing Elements of BERT
Ashish Khetan, Zohar Karnin
Machine Learning for NLP Long Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5B: Jul 6
(21:00-22:00 GMT)
Abstract:
Transformers have gradually become a key component for many state-of-the-art natural language representation models. A recent Transformer based model- BERTachieved state-of-the-art results on various natural language processing tasks, including GLUE, SQuAD v1.1, and SQuAD v2.0. This model however is computationally prohibitive and has a huge number of parameters. In this work we revisit the architecture choices of BERT in efforts to obtain a lighter model. We focus on reducing the number of parameters yet our methods can be applied towards other objectives such FLOPs or latency. We show that much efficient light BERT models can be obtained by reducing algorithmically chosen correct architecture design dimensions rather than reducing the number of Transformer encoder layers. In particular, our schuBERT gives 6.6% higher average accuracy on GLUE and SQuAD datasets as compared to BERT with three encoder layers while having the same number of parameters.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
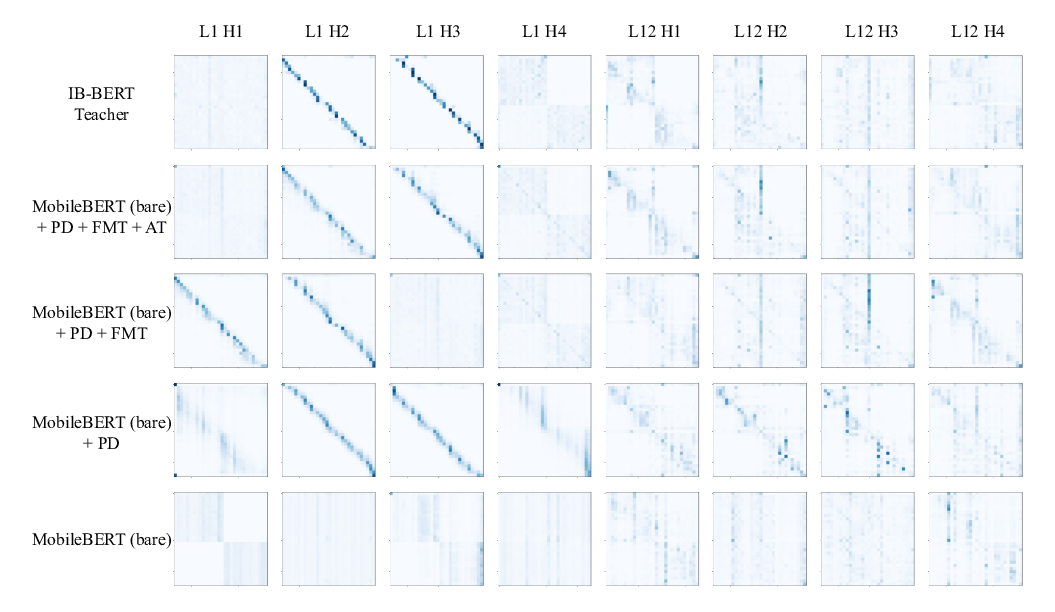
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou,
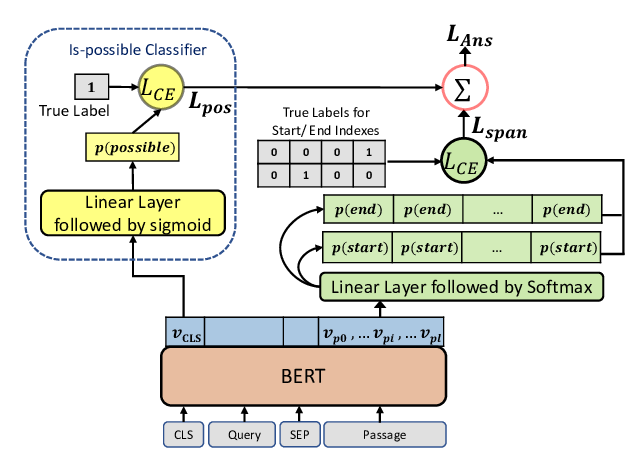
Span Selection Pre-training for Question Answering
Michael Glass, Alfio Gliozzo, Rishav Chakravarti, Anthony Ferritto, Lin Pan, G P Shrivatsa Bhargav, Dinesh Garg, Avi Sil,
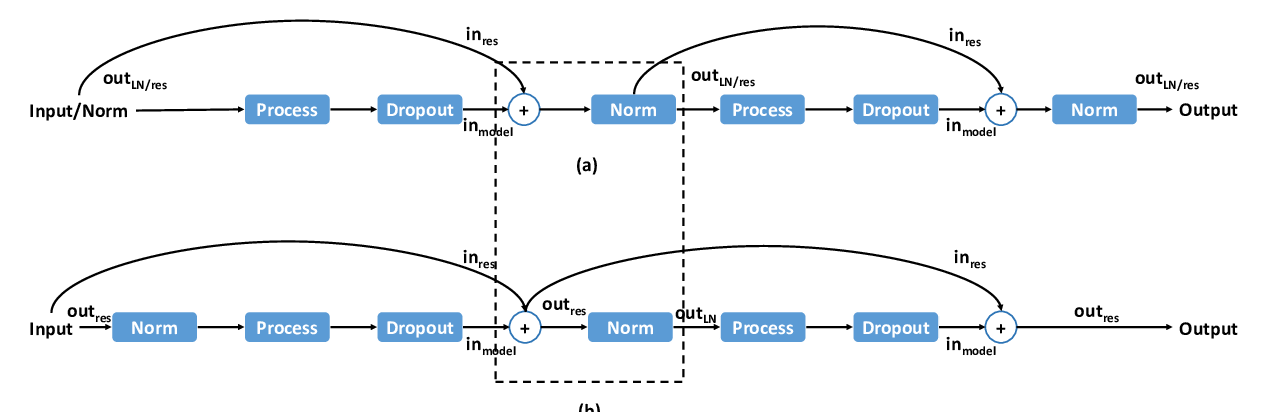
Lipschitz Constrained Parameter Initialization for Deep Transformers
Hongfei Xu, Qiuhui Liu, Josef van Genabith, Deyi Xiong, Jingyi Zhang,
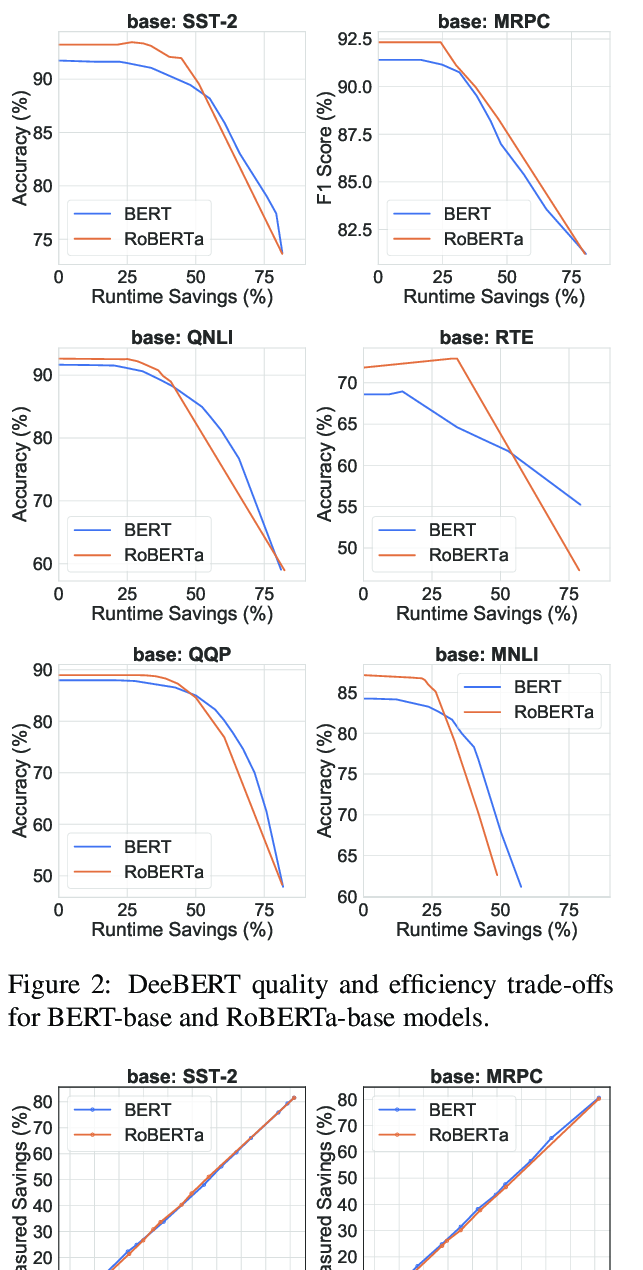
DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, Jimmy Lin,