Leveraging Monolingual Data with Self-Supervision for Multilingual Neural Machine Translation
Aditya Siddhant, Ankur Bapna, Yuan Cao, Orhan Firat, Mia Chen, Sneha Kudugunta, Naveen Arivazhagan, Yonghui Wu
Machine Translation Short Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5A: Jul 6
(20:00-21:00 GMT)
Abstract:
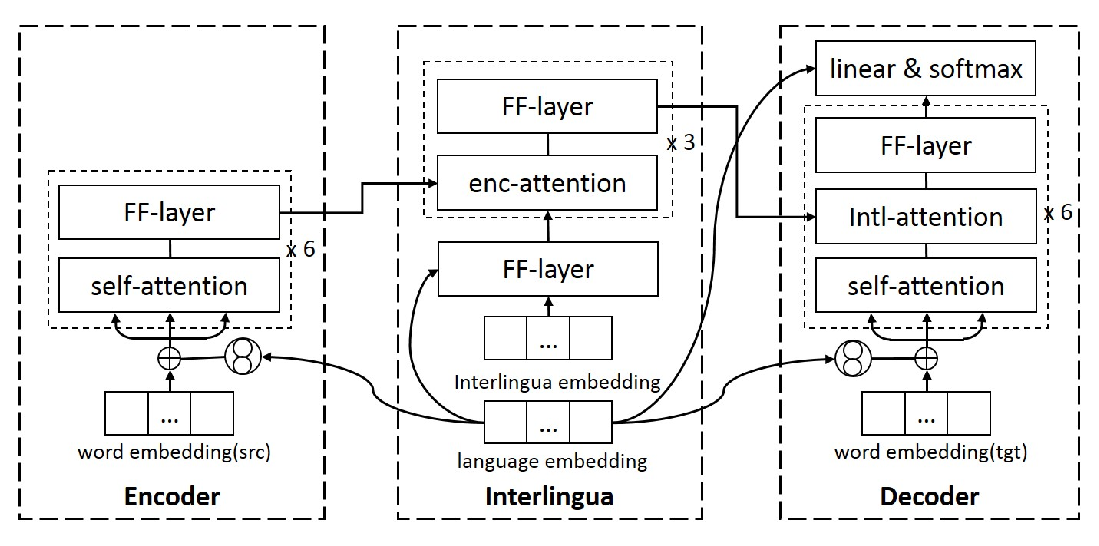
Over the last few years two promising research directions in low-resource neural machine translation (NMT) have emerged. The first focuses on utilizing high-resource languages to improve the quality of low-resource languages via multilingual NMT. The second direction employs monolingual data with self-supervision to pre-train translation models, followed by fine-tuning on small amounts of supervised data. In this work, we join these two lines of research and demonstrate the efficacy of monolingual data with self-supervision in multilingual NMT. We offer three major results: (i) Using monolingual data significantly boosts the translation quality of low-resource languages in multilingual models. (ii) Self-supervision improves zero-shot translation quality in multilingual models. (iii) Leveraging monolingual data with self-supervision provides a viable path towards adding new languages to multilingual models, getting up to 33 BLEU on ro-en translation without any parallel data or back-translation.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation
Biao Zhang, Philip Williams, Ivan Titov, Rico Sennrich,
Multi-Task Neural Model for Agglutinative Language Translation
Yirong Pan, Xiao Li, Yating Yang, Rui Dong,
Unsupervised Multilingual Sentence Embeddings for Parallel Corpus Mining
Ivana Kvapilíková, Mikel Artetxe, Gorka Labaka, Eneko Agirre, Ondřej Bojar,
Language-aware Interlingua for Multilingual Neural Machine Translation
Changfeng Zhu, Heng Yu, Shanbo Cheng, Weihua Luo,