Estimating the influence of auxiliary tasks for multi-task learning of sequence tagging tasks
Fynn Schröder, Chris Biemann
Machine Learning for NLP Long Paper
Session 6A: Jul 7
(05:00-06:00 GMT)

Session 7B: Jul 7
(09:00-10:00 GMT)
Abstract:
Multi-task learning (MTL) and transfer learning (TL) are techniques to overcome the issue of data scarcity when training state-of-the-art neural networks. However, finding beneficial auxiliary datasets for MTL or TL is a time- and resource-consuming trial-and-error approach. We propose new methods to automatically assess the similarity of sequence tagging datasets to identify beneficial auxiliary data for MTL or TL setups. Our methods can compute the similarity between any two sequence tagging datasets, \ie they do not need to be annotated with the same tagset or multiple labels in parallel. Additionally, our methods take tokens and their labels into account, which is more robust than only using either of them as an information source, as conducted in prior work. We empirically show that our similarity measures correlate with the change in test score of neural networks that use the auxiliary dataset for MTL to increase the main task performance. We provide an efficient, open-source implementation.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
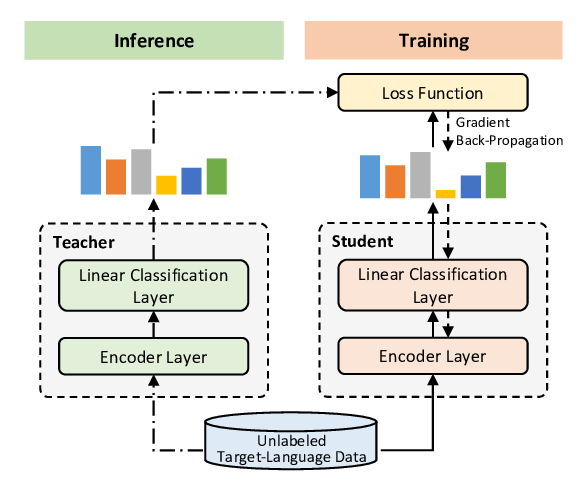
Single-/Multi-Source Cross-Lingual NER via Teacher-Student Learning on Unlabeled Data in Target Language
Qianhui Wu, Zijia Lin, Börje Karlsson, Jian-Guang Lou, Biqing Huang,
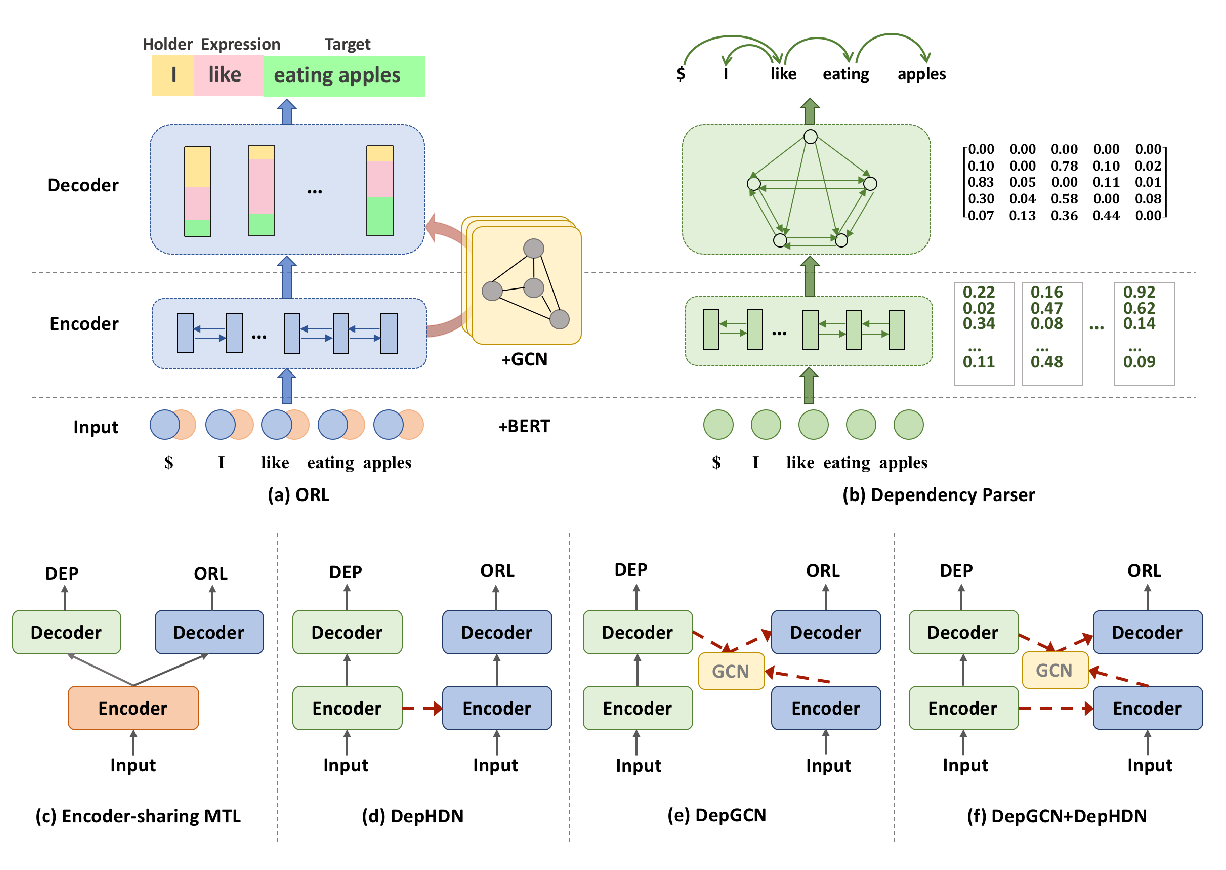
Syntax-Aware Opinion Role Labeling with Dependency Graph Convolutional Networks
Bo Zhang, Yue Zhang, Rui Wang, Zhenghua Li, Min Zhang,
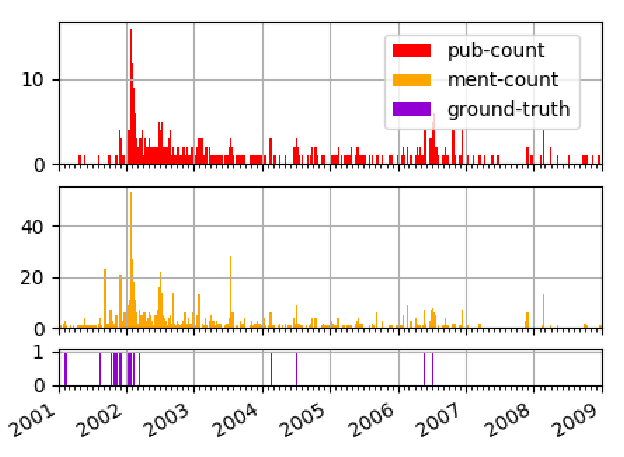
Examining the State-of-the-Art in News Timeline Summarization
Demian Gholipour Ghalandari, Georgiana Ifrim,
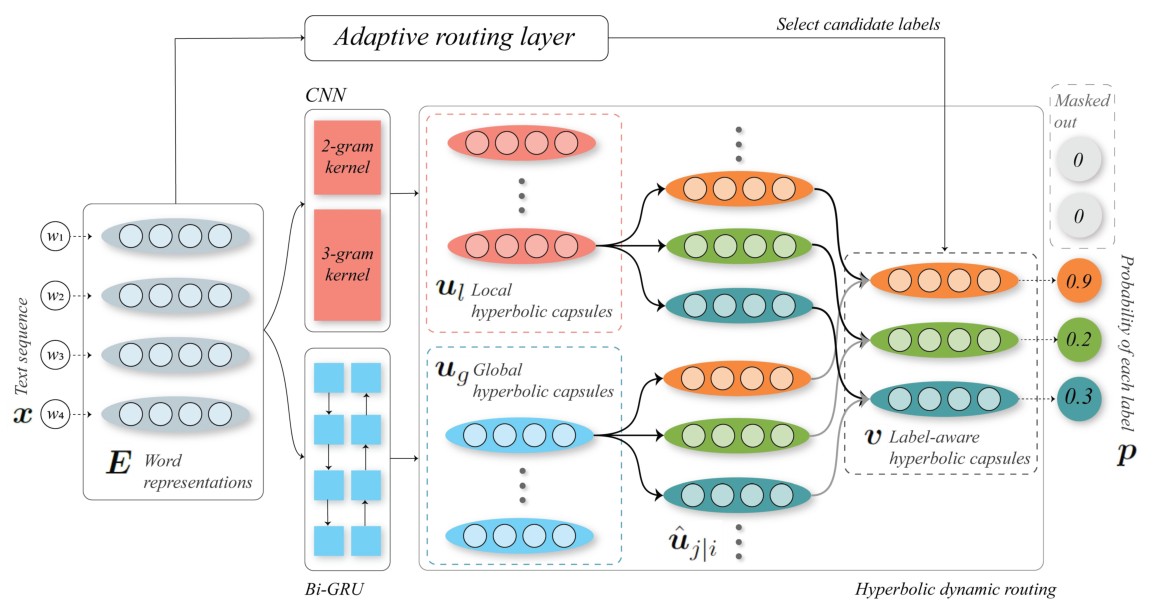
Hyperbolic Capsule Networks for Multi-Label Classification
Boli Chen, Xin Huang, Lin Xiao, Liping Jing,