A Joint Model for Document Segmentation and Segment Labeling
Joe Barrow, Rajiv Jain, Vlad Morariu, Varun Manjunatha, Douglas Oard, Philip Resnik
Information Retrieval and Text Mining Long Paper
Session 1A: Jul 6
(05:00-06:00 GMT)

Session 3A: Jul 6
(12:00-13:00 GMT)
Abstract:
Text segmentation aims to uncover latent structure by dividing text from a document into coherent sections. Where previous work on text segmentation considers the tasks of document segmentation and segment labeling separately, we show that the tasks contain complementary information and are best addressed jointly. We introduce Segment Pooling LSTM (S-LSTM), which is capable of jointly segmenting a document and labeling segments. In support of joint training, we develop a method for teaching the model to recover from errors by aligning the predicted and ground truth segments. We show that S-LSTM reduces segmentation error by 30% on average, while also improving segment labeling.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
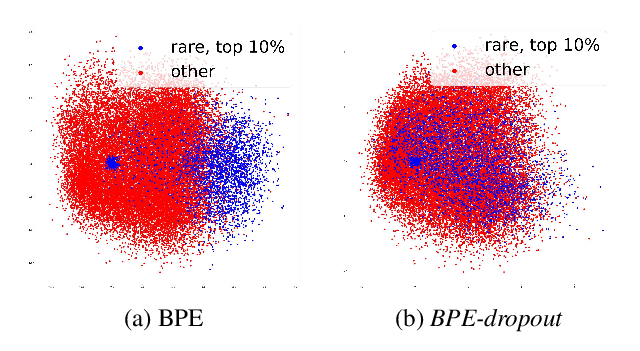
Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
Hongyu Gong, Yelong Shen, Dian Yu, Jianshu Chen, Dong Yu,
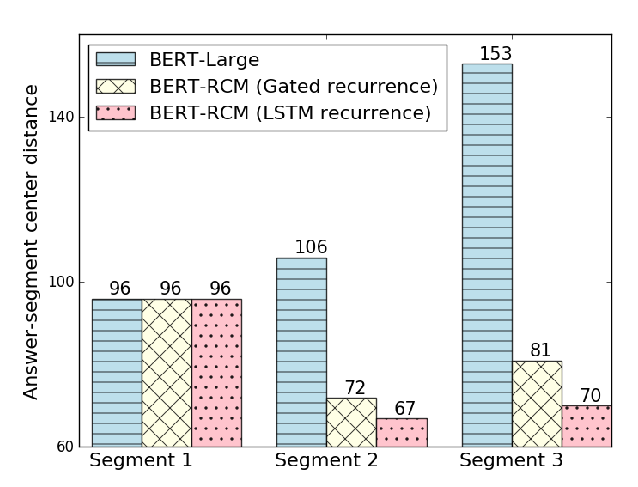
Learning to Recover from Multi-Modality Errors for Non-Autoregressive Neural Machine Translation
Qiu Ran, Yankai Lin, Peng Li, Jie Zhou,
A Graph-based Model for Joint Chinese Word Segmentation and Dependency Parsing
Hang Yan, Xipeng Qiu, Xuanjing Huang,
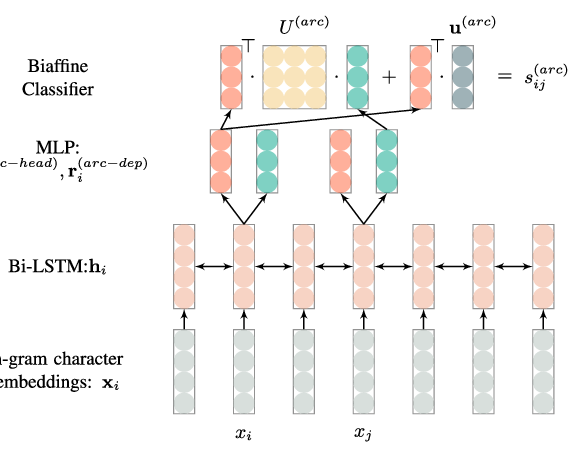
BPE-Dropout: Simple and Effective Subword Regularization
Ivan Provilkov, Dmitrii Emelianenko, Elena Voita,