BPE-Dropout: Simple and Effective Subword Regularization
Ivan Provilkov, Dmitrii Emelianenko, Elena Voita
Machine Translation Long Paper
Session 3B: Jul 6
(13:00-14:00 GMT)

Session 4B: Jul 6
(18:00-19:00 GMT)
Abstract:
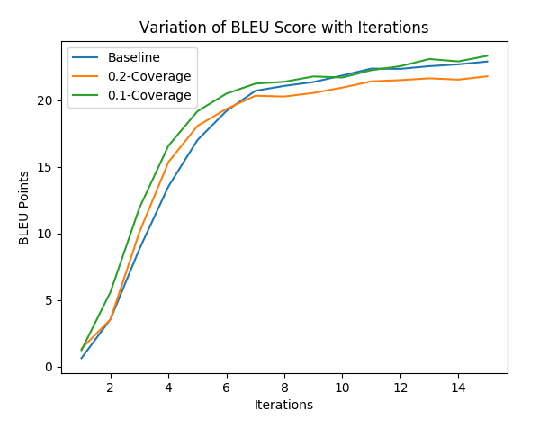
Subword segmentation is widely used to address the open vocabulary problem in machine translation. The dominant approach to subword segmentation is Byte Pair Encoding (BPE), which keeps the most frequent words intact while splitting the rare ones into multiple tokens. While multiple segmentations are possible even with the same vocabulary, BPE splits words into unique sequences; this may prevent a model from better learning the compositionality of words and being robust to segmentation errors. So far, the only way to overcome this BPE imperfection, its deterministic nature, was to create another subword segmentation algorithm (Kudo, 2018). In contrast, we show that BPE itself incorporates the ability to produce multiple segmentations of the same word. We introduce BPE-dropout - simple and effective subword regularization method based on and compatible with conventional BPE. It stochastically corrupts the segmentation procedure of BPE, which leads to producing multiple segmentations within the same fixed BPE framework. Using BPE-dropout during training and the standard BPE during inference improves translation quality up to 2.3 BLEU compared to BPE and up to 0.9 BLEU compared to the previous subword regularization.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Dynamic Programming Encoding for Subword Segmentation in Neural Machine Translation
Xuanli He, Gholamreza Haffari, Mohammad Norouzi,
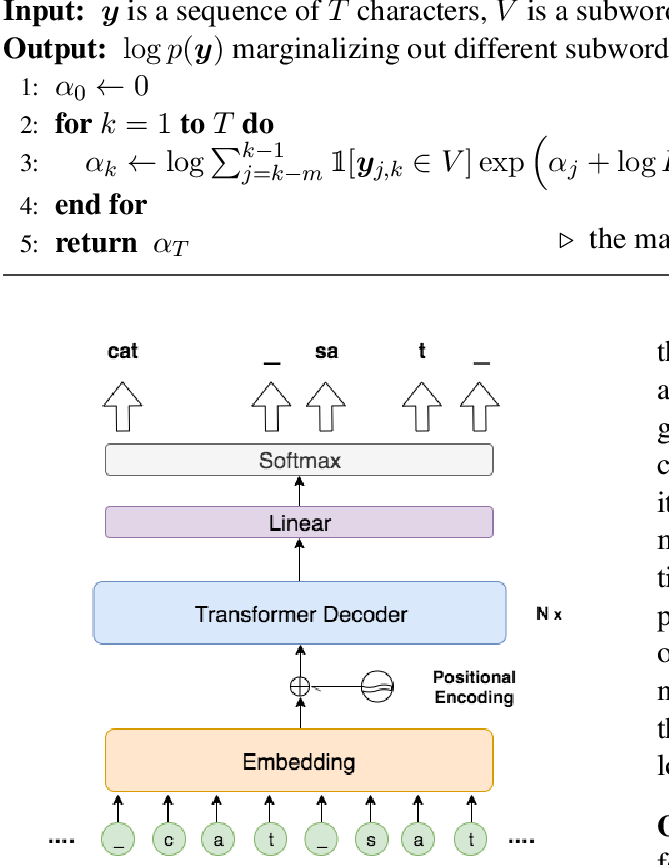
A Joint Model for Document Segmentation and Segment Labeling
Joe Barrow, Rajiv Jain, Vlad Morariu, Varun Manjunatha, Douglas Oard, Philip Resnik,
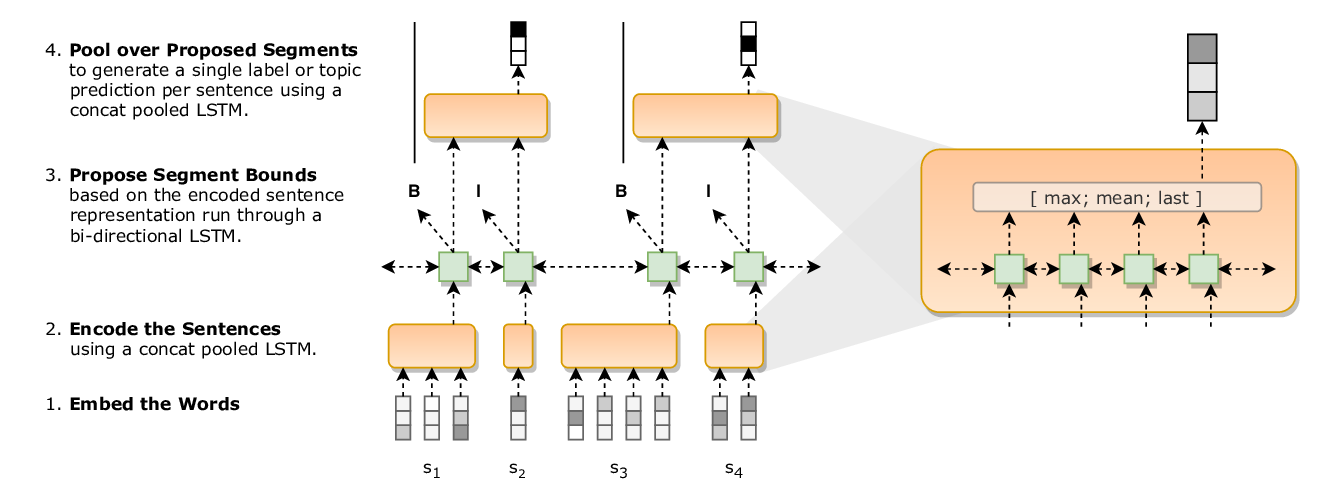
Evaluating Robustness to Input Perturbations for Neural Machine Translation
Xing Niu, Prashant Mathur, Georgiana Dinu, Yaser Al-Onaizan,
Checkpoint Reranking: An Approach to Select Better Hypothesis for Neural Machine Translation Systems
Vinay Pandramish, Dipti Misra Sharma,