On the Robustness of Language Encoders against Grammatical Errors
Fan Yin, Quanyu Long, Tao Meng, Kai-Wei Chang
Interpretability and Analysis of Models for NLP Long Paper
Session 6B: Jul 7
(06:00-07:00 GMT)

Session 8A: Jul 7
(12:00-13:00 GMT)
Abstract:
We conduct a thorough study to diagnose the behaviors of pre-trained language encoders (ELMo, BERT, and RoBERTa) when confronted with natural grammatical errors. Specifically, we collect real grammatical errors from non-native speakers and conduct adversarial attacks to simulate these errors on clean text data. We use this approach to facilitate debugging models on downstream applications. Results confirm that the performance of all tested models is affected but the degree of impact varies. To interpret model behaviors, we further design a linguistic acceptability task to reveal their abilities in identifying ungrammatical sentences and the position of errors. We find that fixed contextual encoders with a simple classifier trained on the prediction of sentence correctness are able to locate error positions. We also design a cloze test for BERT and discover that BERT captures the interaction between errors and specific tokens in context. Our results shed light on understanding the robustness and behaviors of language encoders against grammatical errors.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
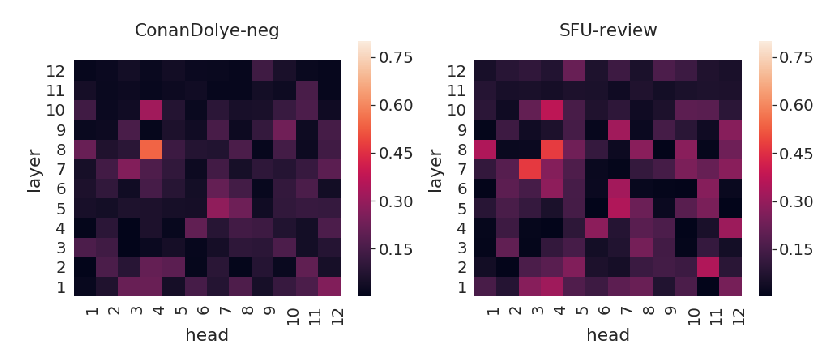
How does BERT's attention change when you fine-tune? An analysis methodology and a case study in negation scope
Yiyun Zhao, Steven Bethard,
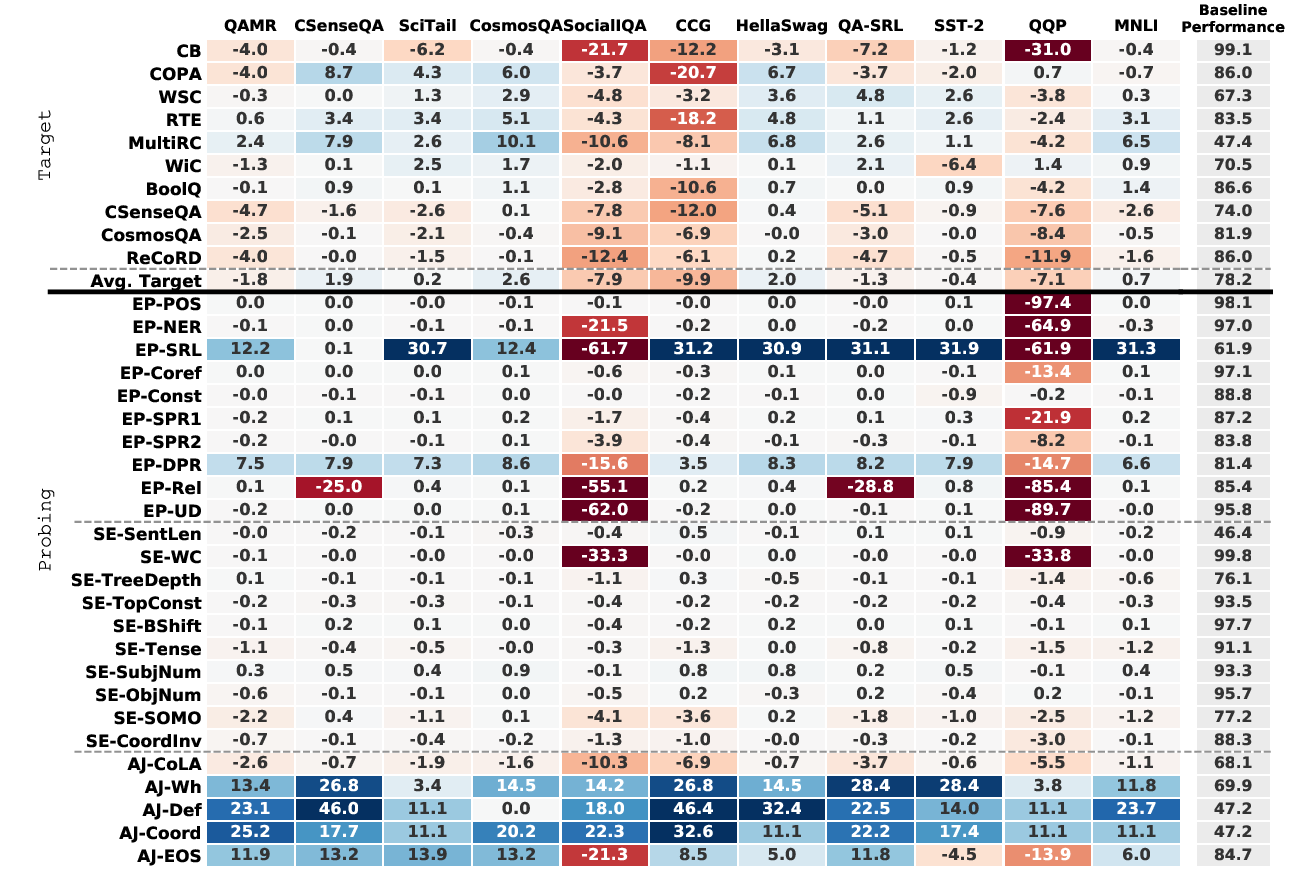
Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?
Yada Pruksachatkun, Jason Phang, Haokun Liu, Phu Mon Htut, Xiaoyi Zhang, Richard Yuanzhe Pang, Clara Vania, Katharina Kann, Samuel R. Bowman,
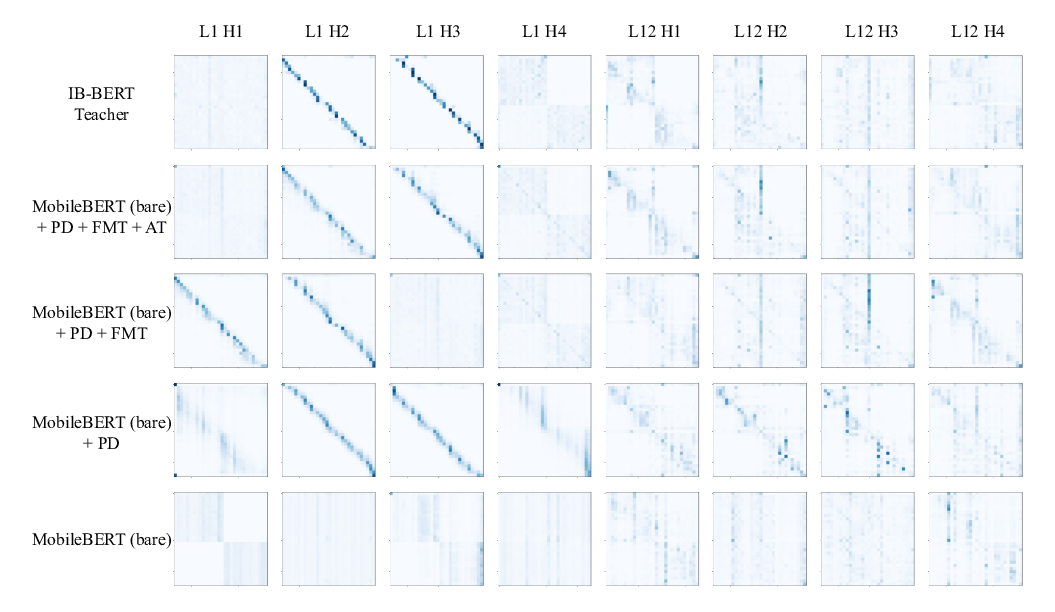
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou,
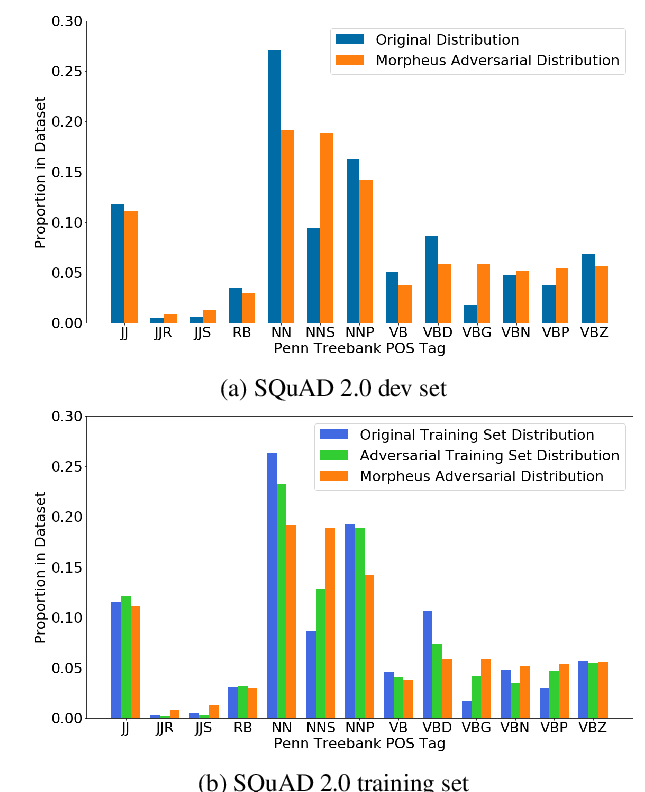
It’s Morphin’ Time! Combating Linguistic Discrimination with Inflectional Perturbations
Samson Tan, Shafiq Joty, Min-Yen Kan, Richard Socher,