How Accents Confound: Probing for Accent Information in End-to-End Speech Recognition Systems
Archiki Prasad, Preethi Jyothi
Speech and Multimodality Long Paper
Session 6B: Jul 7
(06:00-07:00 GMT)

Session 8B: Jul 7
(13:00-14:00 GMT)
Abstract:
In this work, we present a detailed analysis of how accent information is reflected in the internal representation of speech in an end-to-end automatic speech recognition (ASR) system. We use a state-of-the-art end-to-end ASR system, comprising convolutional and recurrent layers, that is trained on a large amount of US-accented English speech and evaluate the model on speech samples from seven different English accents. We examine the effects of accent on the internal representation using three main probing techniques: a) Gradient-based explanation methods, b) Information-theoretic measures, and c) Outputs of accent and phone classifiers. We find different accents exhibiting similar trends irrespective of the probing technique used. We also find that most accent information is encoded within the first recurrent layer, which is suggestive of how one could adapt such an end-to-end model to learn representations that are invariant to accents.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Speech Translation and the End-to-End Promise: Taking Stock of Where We Are
Matthias Sperber, Matthias Paulik,

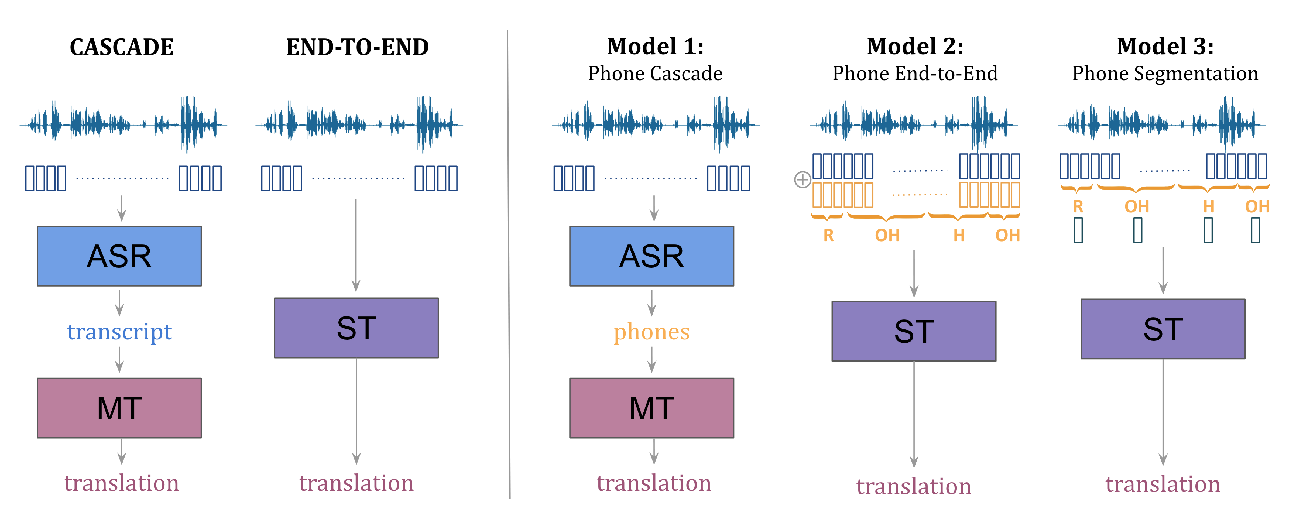
Programming in Natural Language with fuSE: Synthesizing Methods from Spoken Utterances Using Deep Natural Language Understanding
Sebastian Weigelt, Vanessa Steurer, Tobias Hey, Walter F. Tichy,
Learning to Understand Child-directed and Adult-directed Speech
Lieke Gelderloos, Grzegorz Chrupała, Afra Alishahi,