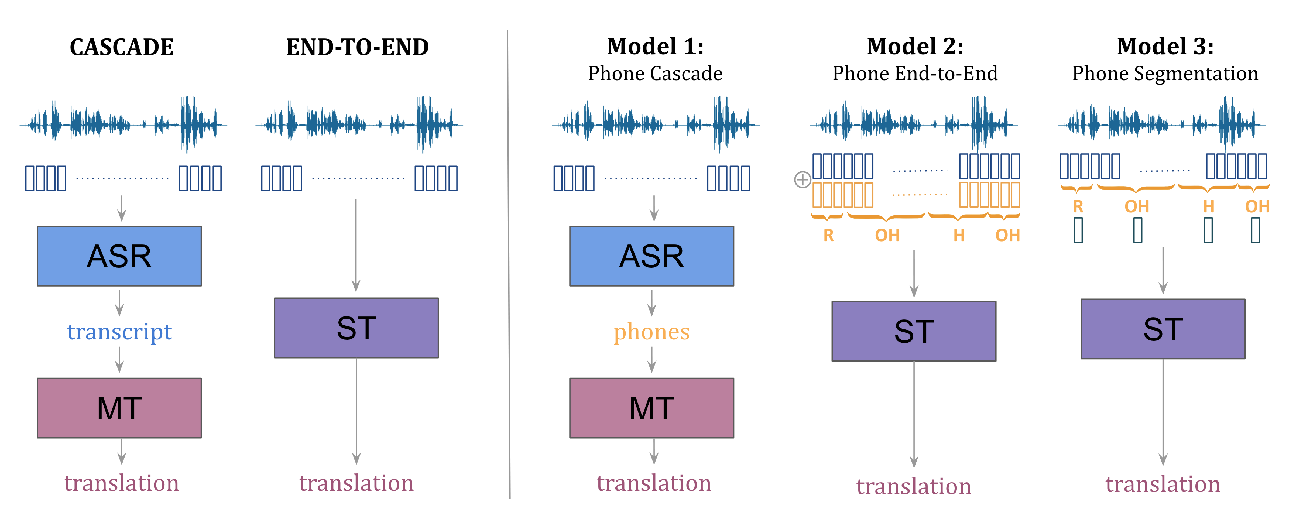
Speech Translation and the End-to-End Promise: Taking Stock of Where We Are
Matthias Sperber, Matthias Paulik
Theme Long Paper
Session 12B: Jul 8
(09:00-10:00 GMT)

Session 13B: Jul 8
(13:00-14:00 GMT)
Abstract:
Over its three decade history, speech translation has experienced several shifts in its primary research themes; moving from loosely coupled cascades of speech recognition and machine translation, to exploring questions of tight coupling, and finally to end-to-end models that have recently attracted much attention. This paper provides a brief survey of these developments, along with a discussion of the main challenges of traditional approaches which stem from committing to intermediate representations from the speech recognizer, and from training cascaded models separately towards different objectives. Recent end-to-end modeling techniques promise a principled way of overcoming these issues by allowing joint training of all model components and removing the need for explicit intermediate representations. However, a closer look reveals that many end-to-end models fall short of solving these issues, due to compromises made to address data scarcity. This paper provides a unifying categorization and nomenclature that covers both traditional and recent approaches and that may help researchers by highlighting both trade-offs and open research questions.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
How Accents Confound: Probing for Accent Information in End-to-End Speech Recognition Systems
Archiki Prasad, Preethi Jyothi,
End-to-End Neural Pipeline for Goal-Oriented Dialogue Systems using GPT-2
Donghoon Ham, Jeong-Gwan Lee, Youngsoo Jang, Kee-Eung Kim,