Max-Margin Incremental CCG Parsing
Miloš Stanojević, Mark Steedman
Syntax: Tagging, Chunking and Parsing Long Paper
Session 7A: Jul 7
(08:00-09:00 GMT)

Session 8A: Jul 7
(12:00-13:00 GMT)
Abstract:
Incremental syntactic parsing has been an active research area both for cognitive scientists trying to model human sentence processing and for NLP researchers attempting to combine incremental parsing with language modelling for ASR and MT. Most effort has been directed at designing the right transition mechanism, but less has been done to answer the question of what a probabilistic model for those transition parsers should look like. A very incremental transition mechanism of a recently proposed CCG parser when trained in straightforward locally normalised discriminative fashion produces very bad results on English CCGbank. We identify three biases as the causes of this problem: label bias, exposure bias and imbalanced probabilities bias. While known techniques for tackling these biases improve results, they still do not make the parser state of the art. Instead, we tackle all of these three biases at the same time using an improved version of beam search optimisation that minimises all beam search violations instead of minimising only the biggest violation. The new incremental parser gives better results than all previously published incremental CCG parsers, and outperforms even some widely used non-incremental CCG parsers.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
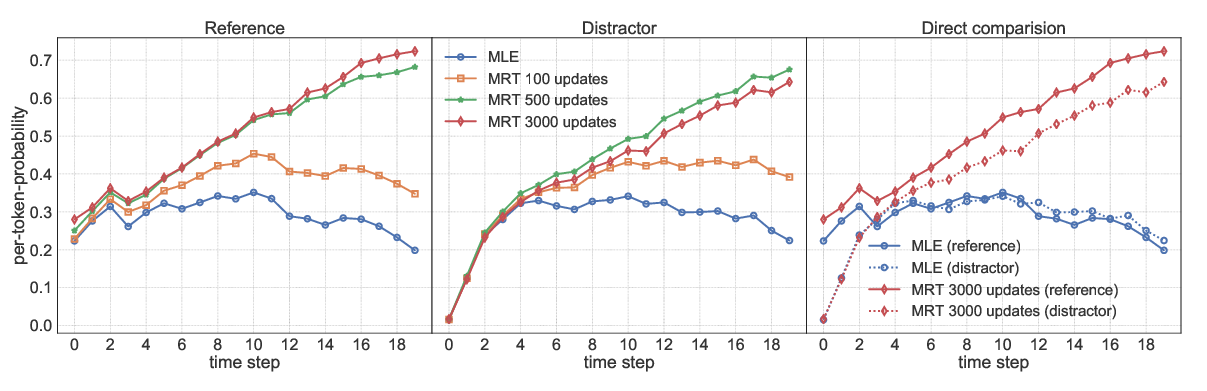
On Exposure Bias, Hallucination and Domain Shift in Neural Machine Translation
Chaojun Wang, Rico Sennrich,
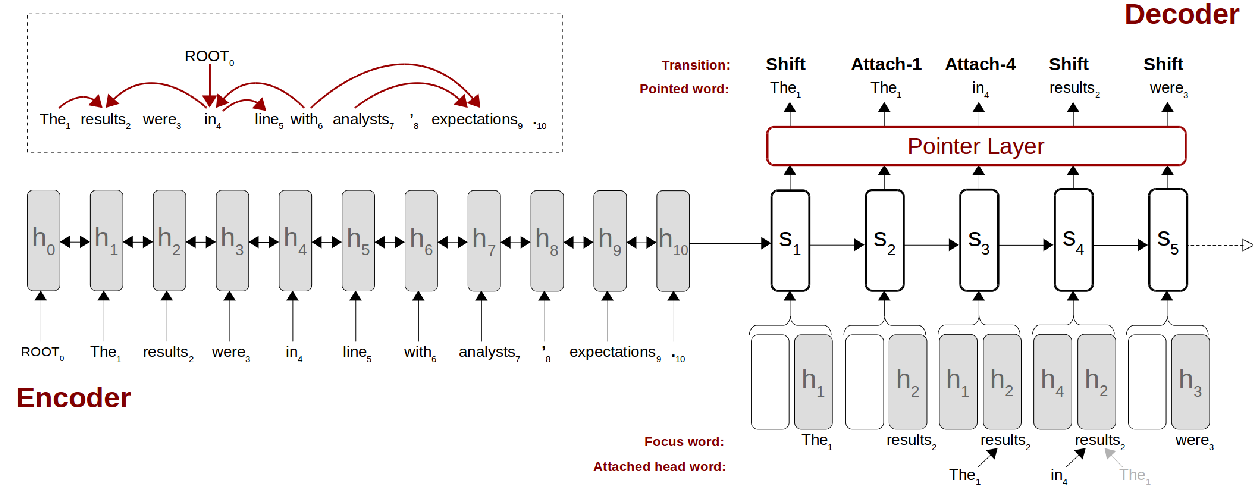
Transition-based Semantic Dependency Parsing with Pointer Networks
Daniel Fernández-González, Carlos Gómez-Rodríguez,
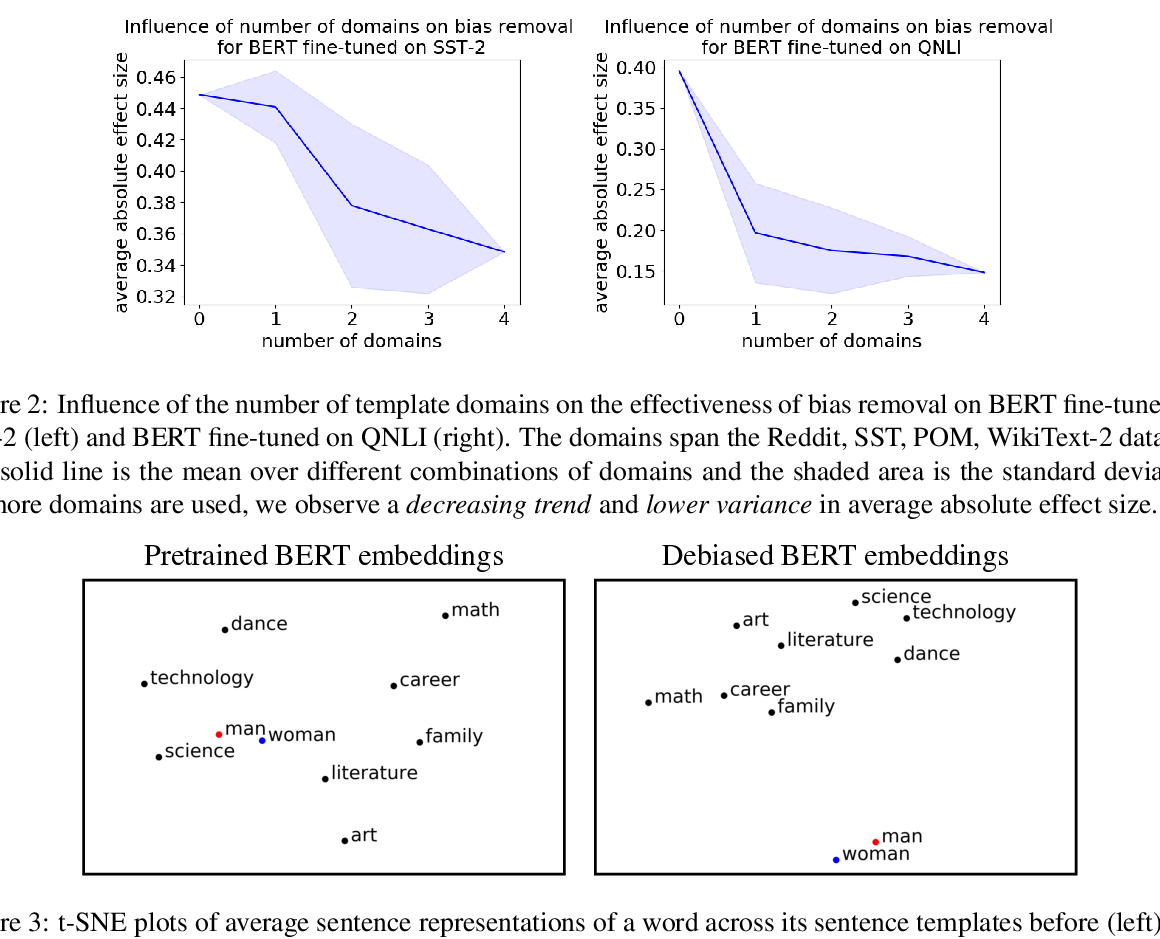
Towards Debiasing Sentence Representations
Paul Pu Liang, Irene Mengze Li, Emily Zheng, Yao Chong Lim, Ruslan Salakhutdinov, Louis-Philippe Morency,