Towards Robustifying NLI Models Against Lexical Dataset Biases
Xiang Zhou, Mohit Bansal
Semantics: Textual Inference and Other Areas of Semantics Long Paper
Session 14B: Jul 8
(18:00-19:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
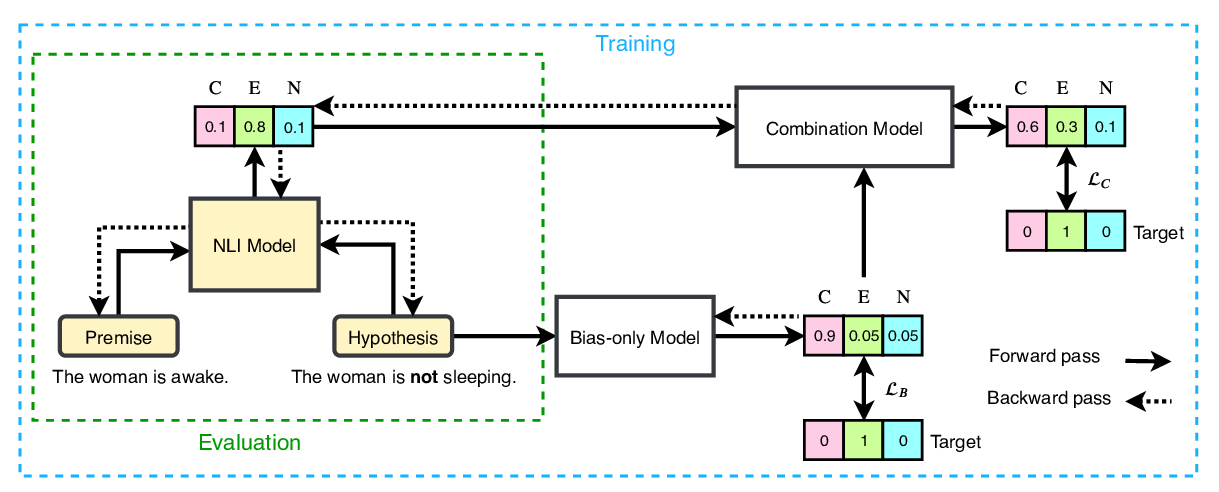
While deep learning models are making fast progress on the task of Natural Language Inference, recent studies have also shown that these models achieve high accuracy by exploiting several dataset biases, and without deep understanding of the language semantics. Using contradiction-word bias and word-overlapping bias as our two bias examples, this paper explores both data-level and model-level debiasing methods to robustify models against lexical dataset biases. First, we debias the dataset through data augmentation and enhancement, but show that the model bias cannot be fully removed via this method. Next, we also compare two ways of directly debiasing the model without knowing what the dataset biases are in advance. The first approach aims to remove the label bias at the embedding level. The second approach employs a bag-of-words sub-model to capture the features that are likely to exploit the bias and prevents the original model from learning these biased features by forcing orthogonality between these two sub-models. We performed evaluations on new balanced datasets extracted from the original MNLI dataset as well as the NLI stress tests, and show that the orthogonality approach is better at debiasing the model while maintaining competitive overall accuracy.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Predictive Biases in Natural Language Processing Models: A Conceptual Framework and Overview
Deven Santosh Shah, H. Andrew Schwartz, Dirk Hovy,
Mitigating Gender Bias Amplification in Distribution by Posterior Regularization
Shengyu Jia, Tao Meng, Jieyu Zhao, Kai-Wei Chang,
End-to-End Bias Mitigation by Modelling Biases in Corpora
Rabeeh Karimi Mahabadi, Yonatan Belinkov, James Henderson,