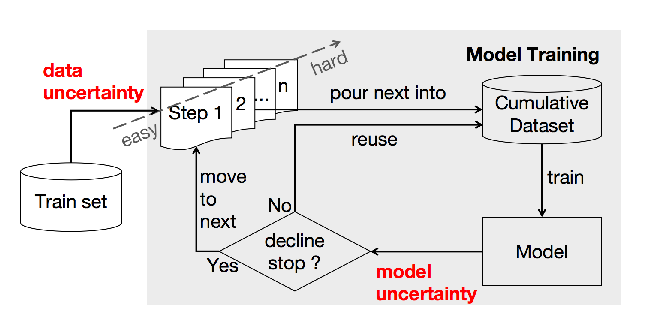
Norm-Based Curriculum Learning for Neural Machine Translation
Xuebo Liu, Houtim Lai, Derek F. Wong, Lidia S. Chao
Machine Translation Long Paper
Session 1A: Jul 6
(05:00-06:00 GMT)

Session 2B: Jul 6
(09:00-10:00 GMT)
Abstract:
A neural machine translation (NMT) system is expensive to train, especially with high-resource settings. As the NMT architectures become deeper and wider, this issue gets worse and worse. In this paper, we aim to improve the efficiency of training an NMT by introducing a novel norm-based curriculum learning method. We use the norm (aka length or module) of a word embedding as a measure of 1) the difficulty of the sentence, 2) the competence of the model, and 3) the weight of the sentence. The norm-based sentence difficulty takes the advantages of both linguistically motivated and model-based sentence difficulties. It is easy to determine and contains learning-dependent features. The norm-based model competence makes NMT learn the curriculum in a fully automated way, while the norm-based sentence weight further enhances the learning of the vector representation of the NMT. Experimental results for the WMT'14 English-German and WMT'17 Chinese-English translation tasks demonstrate that the proposed method outperforms strong baselines in terms of BLEU score (+1.17/+1.56) and training speedup (2.22x/3.33x).
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
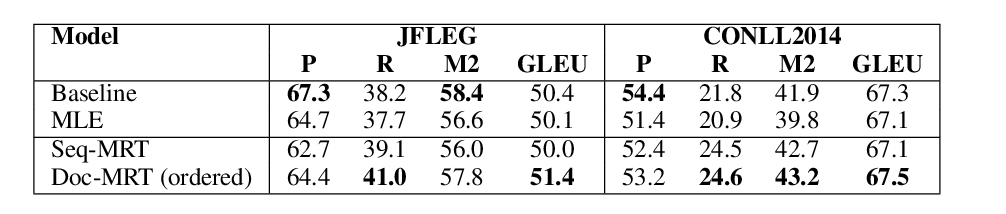
Multiscale Collaborative Deep Models for Neural Machine Translation
Xiangpeng Wei, Heng Yu, Yue Hu, Yue Zhang, Rongxiang Weng, Weihua Luo,
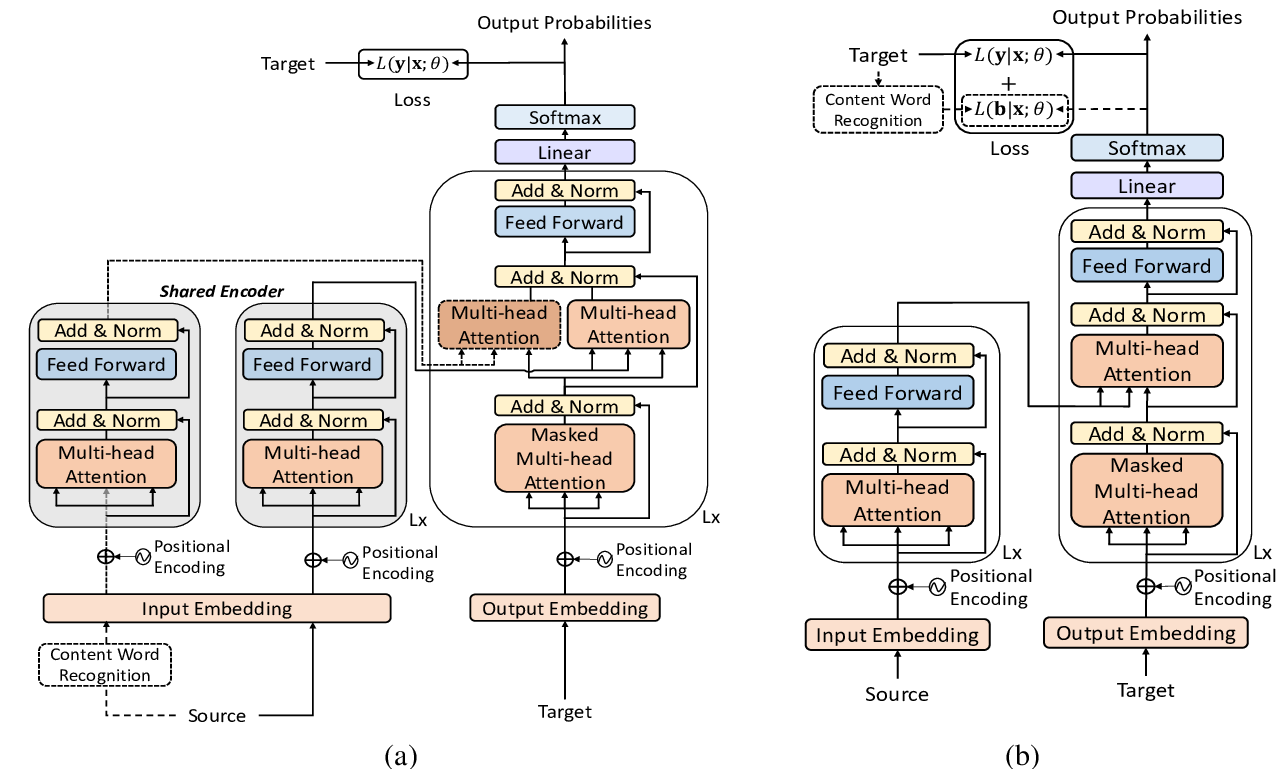
Uncertainty-Aware Curriculum Learning for Neural Machine Translation
Yikai Zhou, Baosong Yang, Derek F. Wong, Yu Wan, Lidia S. Chao,
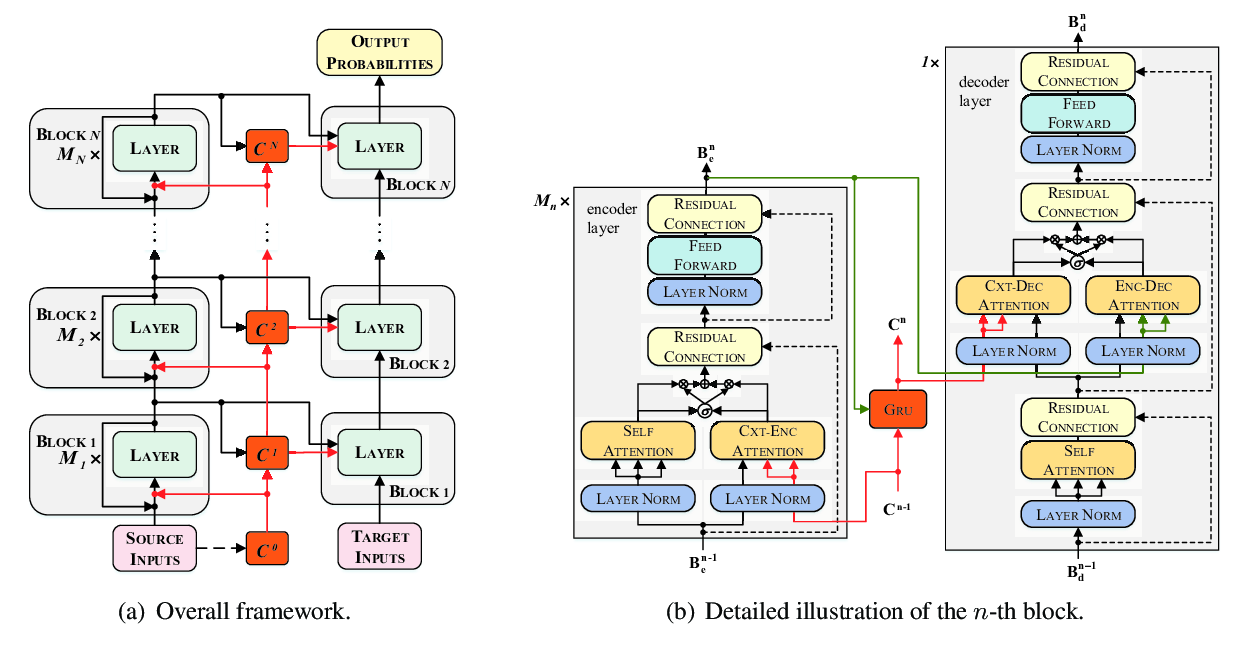
Using Context in Neural Machine Translation Training Objectives
Danielle Saunders, Felix Stahlberg, Bill Byrne,