Clinical Reading Comprehension: A Thorough Analysis of the emrQA Dataset
Xiang Yue, Bernal Jimenez Gutierrez, Huan Sun
Question Answering Long Paper
Session 8A: Jul 7
(12:00-13:00 GMT)

Session 10B: Jul 7
(21:00-22:00 GMT)
Abstract:
Machine reading comprehension has made great progress in recent years owing to large-scale annotated datasets. In the clinical domain, however, creating such datasets is quite difficult due to the domain expertise required for annotation. Recently, Pampari et al. (EMNLP'18) tackled this issue by using expert-annotated question templates and existing i2b2 annotations to create emrQA, the first large-scale dataset for question answering (QA) based on clinical notes. In this paper, we provide an in-depth analysis of this dataset and the clinical reading comprehension (CliniRC) task. From our qualitative analysis, we find that (i) emrQA answers are often incomplete, and (ii) emrQA questions are often answerable without using domain knowledge. From our quantitative experiments, surprising results include that (iii) using a small sampled subset (5%-20%), we can obtain roughly equal performance compared to the model trained on the entire dataset, (iv) this performance is close to human expert's performance, and (v) BERT models do not beat the best performing base model. Following our analysis of the emrQA, we further explore two desired aspects of CliniRC systems: the ability to utilize clinical domain knowledge and to generalize to unseen questions and contexts. We argue that both should be considered when creating future datasets.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Fluent Response Generation for Conversational Question Answering
Ashutosh Baheti, Alan Ritter, Kevin Small,
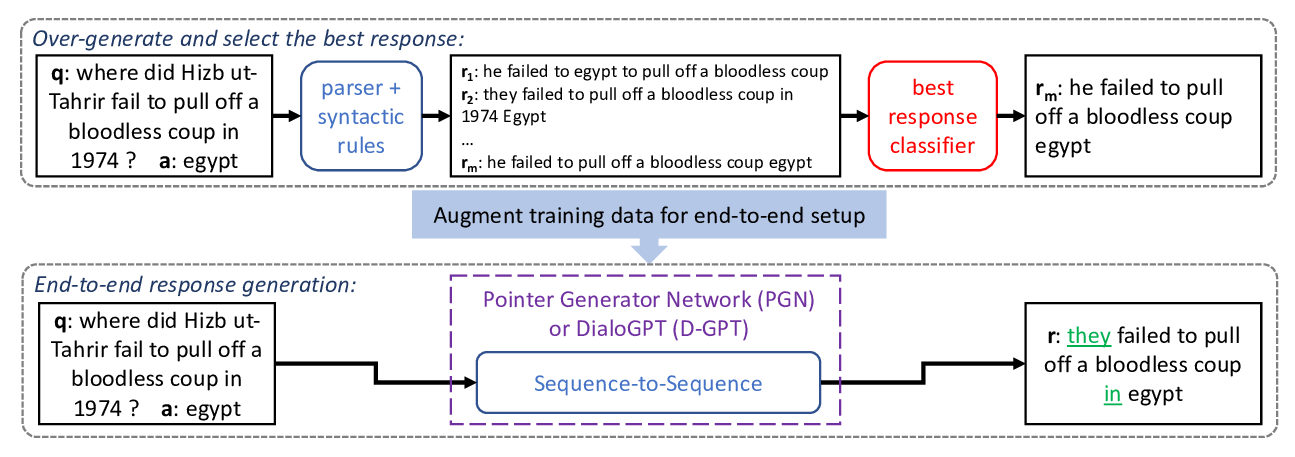
STARC: Structured Annotations for Reading Comprehension
Yevgeni Berzak, Jonathan Malmaud, Roger Levy,
Harvesting and Refining Question-Answer Pairs for Unsupervised QA
Zhongli Li, Wenhui Wang, Li Dong, Furu Wei, Ke Xu,

DoQA - Accessing Domain-Specific FAQs via Conversational QA
Jon Ander Campos, Arantxa Otegi, Aitor Soroa, Jan Deriu, Mark Cieliebak, Eneko Agirre,