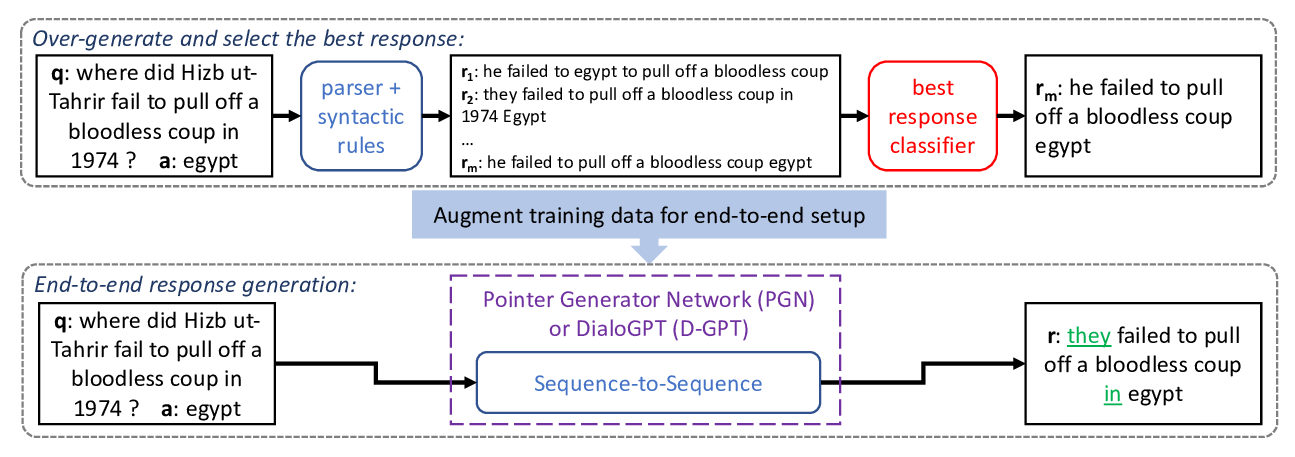
Harvesting and Refining Question-Answer Pairs for Unsupervised QA
Zhongli Li, Wenhui Wang, Li Dong, Furu Wei, Ke Xu
Question Answering Long Paper
Session 11B: Jul 8
(06:00-07:00 GMT)

Session 12B: Jul 8
(09:00-10:00 GMT)
Abstract:
Question Answering (QA) has shown great success thanks to the availability of large-scale datasets and the effectiveness of neural models. Recent research works have attempted to extend these successes to the settings with few or no labeled data available. In this work, we introduce two approaches to improve unsupervised QA. First, we harvest lexically and syntactically divergent questions from Wikipedia to automatically construct a corpus of question-answer pairs (named as RefQA). Second, we take advantage of the QA model to extract more appropriate answers, which iteratively refines data over RefQA. We conduct experiments on SQuAD 1.1, and NewsQA by fine-tuning BERT without access to manually annotated data. Our approach outperforms previous unsupervised approaches by a large margin, and is competitive with early supervised models. We also show the effectiveness of our approach in the few-shot learning setting.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Template-Based Question Generation from Retrieved Sentences for Improved Unsupervised Question Answering
Alexander Fabbri, Patrick Ng, Zhiguo Wang, Ramesh Nallapati, Bing Xiang,
Generating Diverse and Consistent QA pairs from Contexts with Information-Maximizing Hierarchical Conditional VAEs
Dong Bok Lee, Seanie Lee, Woo Tae Jeong, Donghwan Kim, Sung Ju Hwang,
DoQA - Accessing Domain-Specific FAQs via Conversational QA
Jon Ander Campos, Arantxa Otegi, Aitor Soroa, Jan Deriu, Mark Cieliebak, Eneko Agirre,
Fluent Response Generation for Conversational Question Answering
Ashutosh Baheti, Alan Ritter, Kevin Small,