A Transformer-based Approach for Source Code Summarization
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang
Summarization Short Paper
Session 9A: Jul 7
(17:00-18:00 GMT)

Session 10B: Jul 7
(21:00-22:00 GMT)
Abstract:
Generating a readable summary that describes the functionality of a program is known as source code summarization. In this task, learning code representation by modeling the pairwise relationship between code tokens to capture their long-range dependencies is crucial. To learn code representation for summarization, we explore the Transformer model that uses a self-attention mechanism and has shown to be effective in capturing long-range dependencies. In this work, we show that despite the approach is simple, it outperforms the state-of-the-art techniques by a significant margin. We perform extensive analysis and ablation studies that reveal several important findings, e.g., the absolute encoding of source code tokens' position hinders, while relative encoding significantly improves the summarization performance. We have made our code publicly available (https://github.com/wasiahmad/NeuralCodeSum) to facilitate future research.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Incorporating External Knowledge through Pre-training for Natural Language to Code Generation
Frank F. Xu, Zhengbao Jiang, Pengcheng Yin, Bogdan Vasilescu, Graham Neubig,

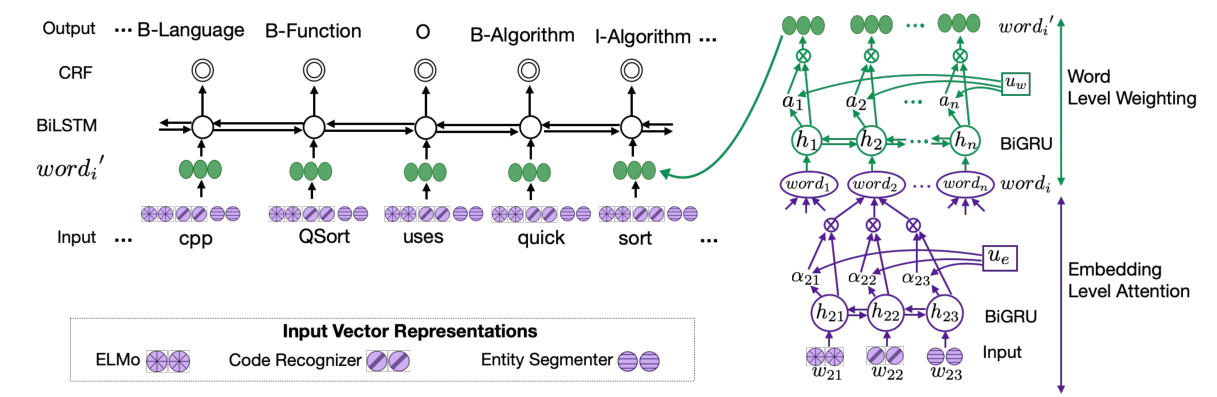
Code and Named Entity Recognition in StackOverflow
Jeniya Tabassum, Mounica Maddela, Wei Xu, Alan Ritter,
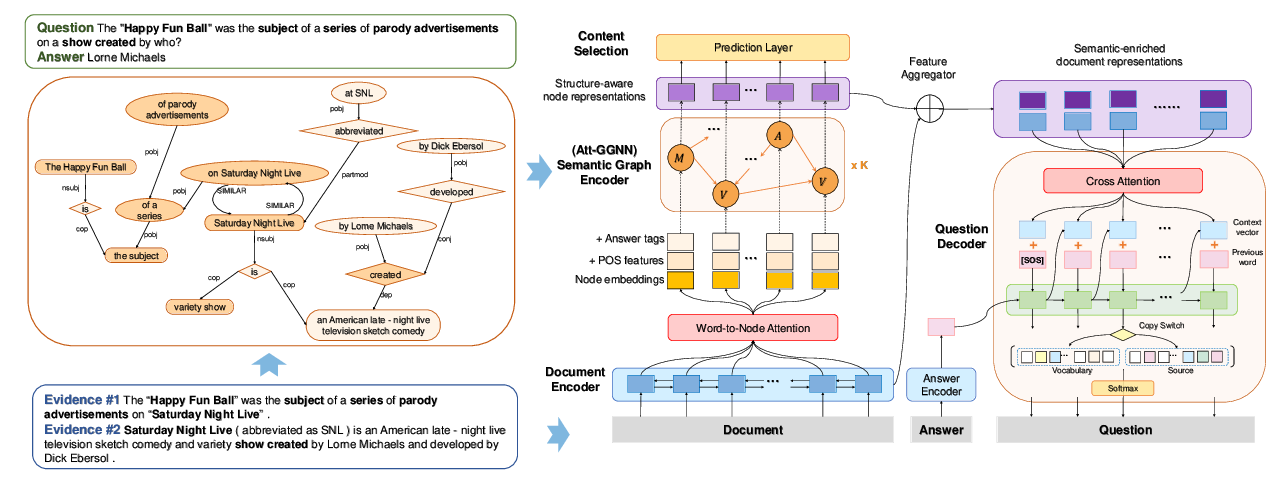
Semantic Graphs for Generating Deep Questions
Liangming Pan, Yuxi Xie, Yansong Feng, Tat-Seng Chua, Min-Yen Kan,
Extractive Summarization as Text Matching
Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang,