Extractive Summarization as Text Matching
Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang
Summarization Long Paper
Session 11A: Jul 8
(05:00-06:00 GMT)

Session 12A: Jul 8
(08:00-09:00 GMT)
Abstract:
This paper creates a paradigm shift with regard to the way we build neural extractive summarization systems. Instead of following the commonly used framework of extracting sentences individually and modeling the relationship between sentences, we formulate the extractive summarization task as a semantic text matching problem, in which a source document and candidate summaries will be (extracted from the original text) matched in a semantic space. Notably, this paradigm shift to semantic matching framework is well-grounded in our comprehensive analysis of the inherent gap between sentence-level and summary-level extractors based on the property of the dataset. Besides, even instantiating the framework with a simple form of a matching model, we have driven the state-of-the-art extractive result on CNN/DailyMail to a new level (44.41 in ROUGE-1). Experiments on the other five datasets also show the effectiveness of the matching framework. We believe the power of this matching-based summarization framework has not been fully exploited. To encourage more instantiations in the future, we have released our codes, processed dataset, as well as generated summaries in {https://github.com/maszhongming/MatchSum}.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
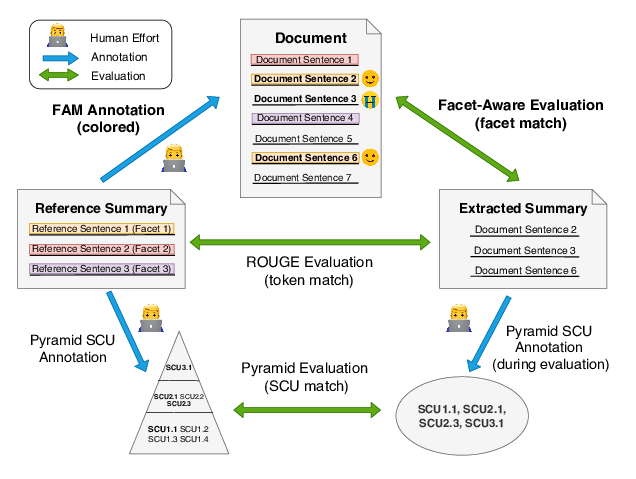
Facet-Aware Evaluation for Extractive Summarization
Yuning Mao, Liyuan Liu, Qi Zhu, Xiang Ren, Jiawei Han,
A Transformer-based Approach for Source Code Summarization
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang,

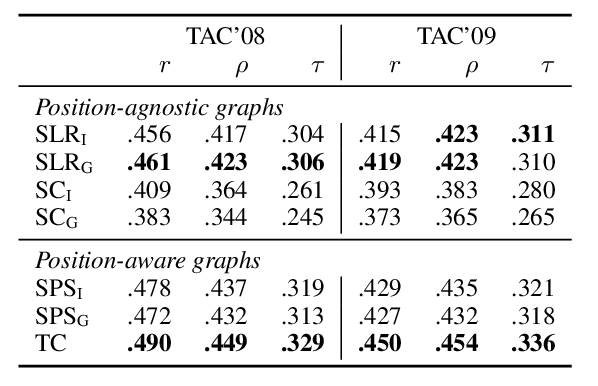
SUPERT: Towards New Frontiers in Unsupervised Evaluation Metrics for Multi-Document Summarization
Yang Gao, Wei Zhao, Steffen Eger,