Multi-Agent Task-Oriented Dialog Policy Learning with Role-Aware Reward Decomposition
Ryuichi Takanobu, Runze Liang, Minlie Huang
Dialogue and Interactive Systems Long Paper
Session 1B: Jul 6
(06:00-07:00 GMT)

Session 3B: Jul 6
(13:00-14:00 GMT)
Abstract:
Many studies have applied reinforcement learning to train a dialog policy and show great promise these years. One common approach is to employ a user simulator to obtain a large number of simulated user experiences for reinforcement learning algorithms. However, modeling a realistic user simulator is challenging. A rule-based simulator requires heavy domain expertise for complex tasks, and a data-driven simulator requires considerable data and it is even unclear how to evaluate a simulator. To avoid explicitly building a user simulator beforehand, we propose Multi-Agent Dialog Policy Learning, which regards both the system and the user as the dialog agents. Two agents interact with each other and are jointly learned simultaneously. The method uses the actor-critic framework to facilitate pretraining and improve scalability. We also propose Hybrid Value Network for the role-aware reward decomposition to integrate role-specific domain knowledge of each agent in the task-oriented dialog. Results show that our method can successfully build a system policy and a user policy simultaneously, and two agents can achieve a high task success rate through conversational interaction.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Learning Efficient Dialogue Policy from Demonstrations through Shaping
Huimin Wang, Baolin Peng, Kam-Fai Wong,
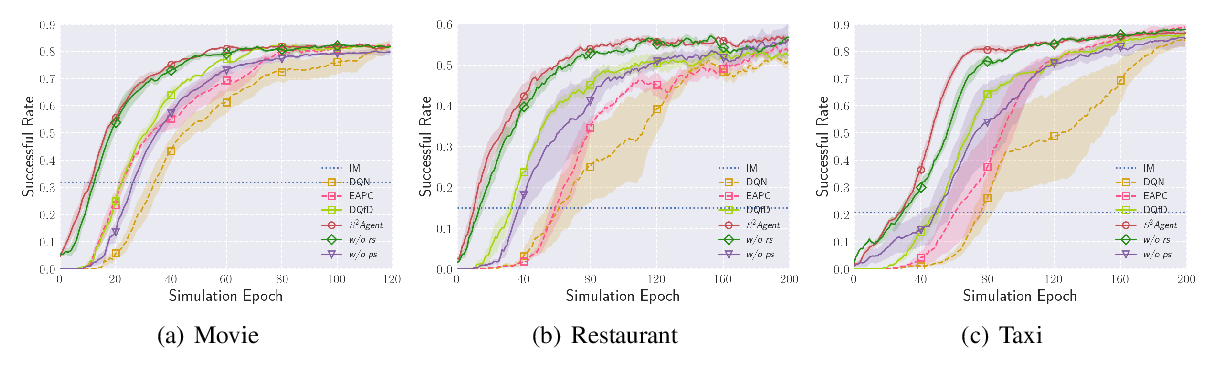
Conversational Graph Grounded Policy Learning for Open-Domain Conversation Generation
Jun Xu, Haifeng Wang, Zheng-Yu Niu, Hua Wu, Wanxiang Che, Ting Liu,
Learning Dialog Policies from Weak Demonstrations
Gabriel Gordon-Hall, Philip John Gorinski, Shay B. Cohen,
Towards Conversational Recommendation over Multi-Type Dialogs
Zeming Liu, Haifeng Wang, Zheng-Yu Niu, Hua Wu, Wanxiang Che, Ting Liu,