FLAT: Chinese NER Using Flat-Lattice Transformer
Xiaonan Li, Hang Yan, Xipeng Qiu, Xuanjing Huang
Information Extraction Short Paper
Session 12A: Jul 8
(08:00-09:00 GMT)

Session 13B: Jul 8
(13:00-14:00 GMT)
Abstract:
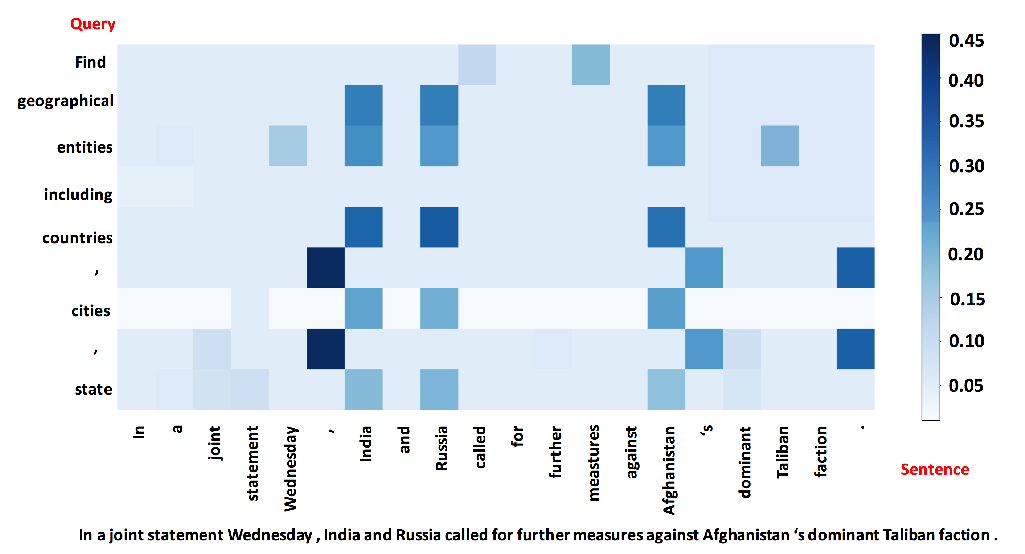
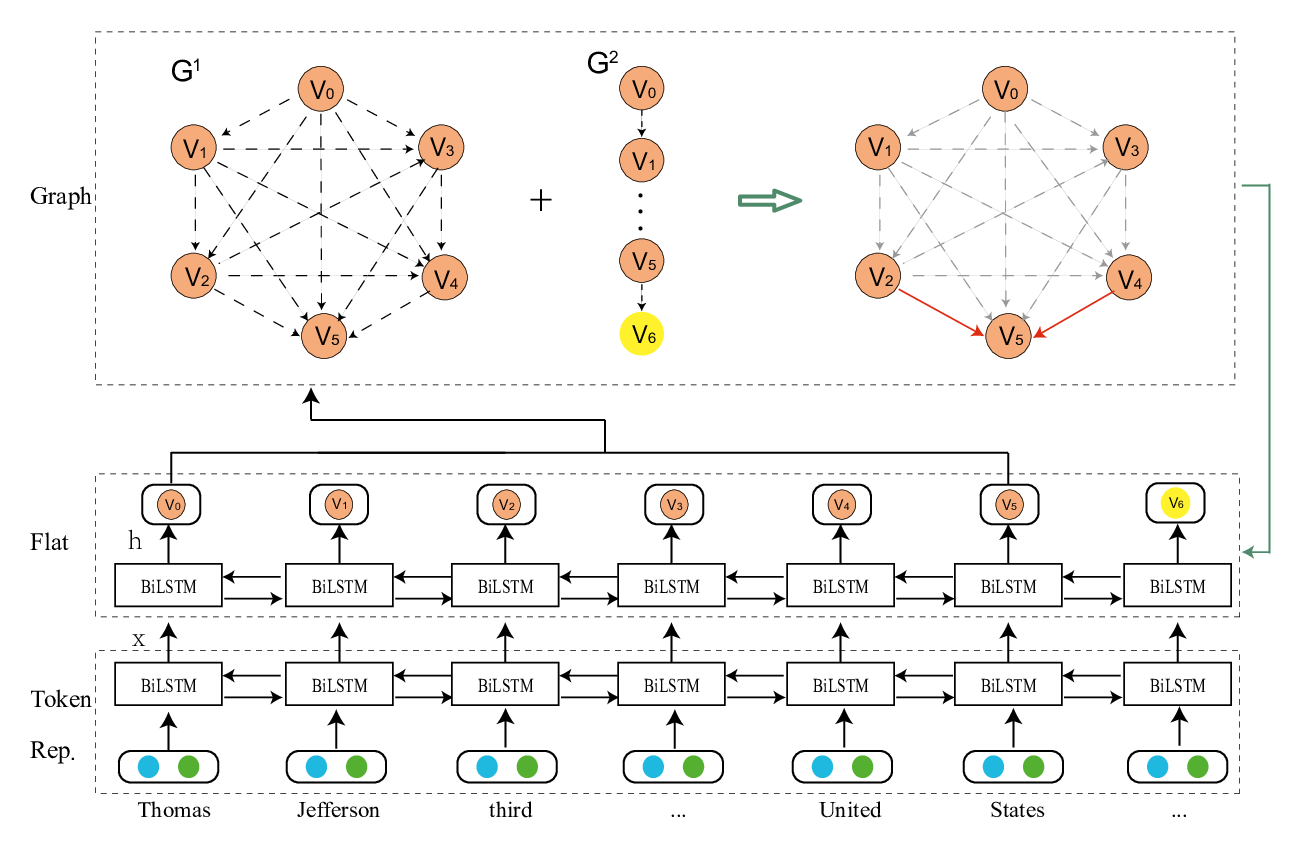
Recently, the character-word lattice structure has been proved to be effective for Chinese named entity recognition (NER) by incorporating the word information. However, since the lattice structure is complex and dynamic, the lattice-based models are hard to fully utilize the parallel computation of GPUs and usually have a low inference speed. In this paper, we propose FLAT: Flat-LAttice Transformer for Chinese NER, which converts the lattice structure into a flat structure consisting of spans. Each span corresponds to a character or latent word and its position in the original lattice. With the power of Transformer and well-designed position encoding, FLAT can fully leverage the lattice information and has an excellent parallel ability. Experiments on four datasets show FLAT outperforms other lexicon-based models in performance and efficiency.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
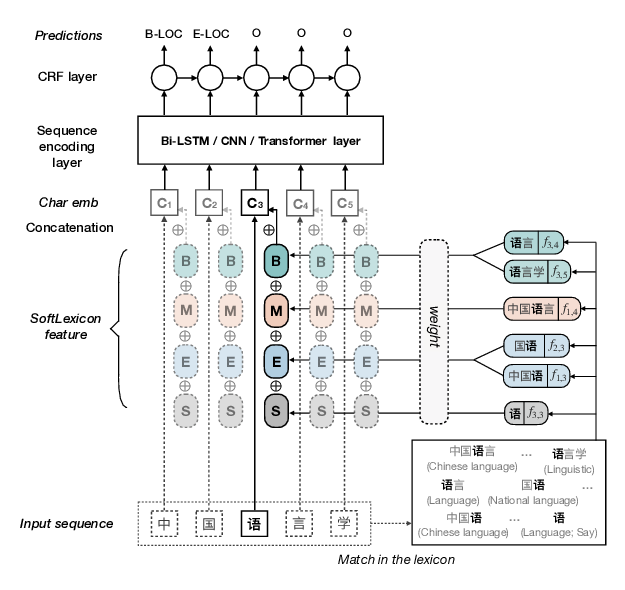
Simplify the Usage of Lexicon in Chinese NER
Ruotian Ma, Minlong Peng, Qi Zhang, Zhongyu Wei, Xuanjing Huang,
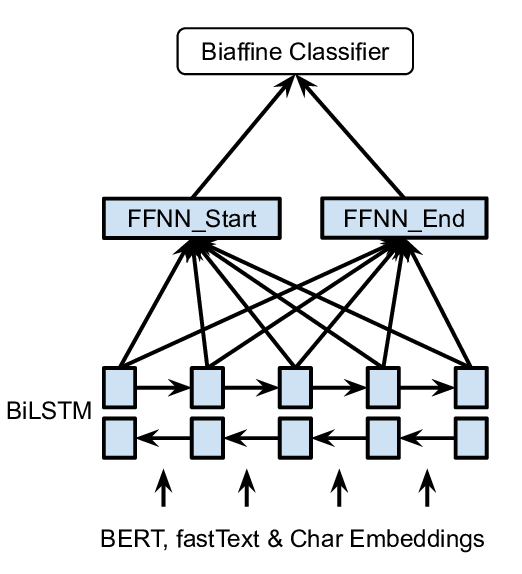
A Unified MRC Framework for Named Entity Recognition
Xiaoya Li, Jingrong Feng, Yuxian Meng, Qinghong Han, Fei Wu, Jiwei Li,