Sentence Meta-Embeddings for Unsupervised Semantic Textual Similarity
Nina Poerner, Ulli Waltinger, Hinrich Schütze
Semantics: Sentence Level Short Paper
Session 12A: Jul 8
(08:00-09:00 GMT)

Session 13A: Jul 8
(12:00-13:00 GMT)
Abstract:
We address the task of unsupervised Semantic Textual Similarity (STS) by ensembling diverse pre-trained sentence encoders into sentence meta-embeddings. We apply, extend and evaluate different meta-embedding methods from the word embedding literature at the sentence level, including dimensionality reduction (Yin and Schütze, 2016), generalized Canonical Correlation Analysis (Rastogi et al., 2015) and cross-view auto-encoders (Bollegala and Bao, 2018). Our sentence meta-embeddings set a new unsupervised State of The Art (SoTA) on the STS Benchmark and on the STS12-STS16 datasets, with gains of between 3.7% and 6.4% Pearson’s r over single-source systems.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
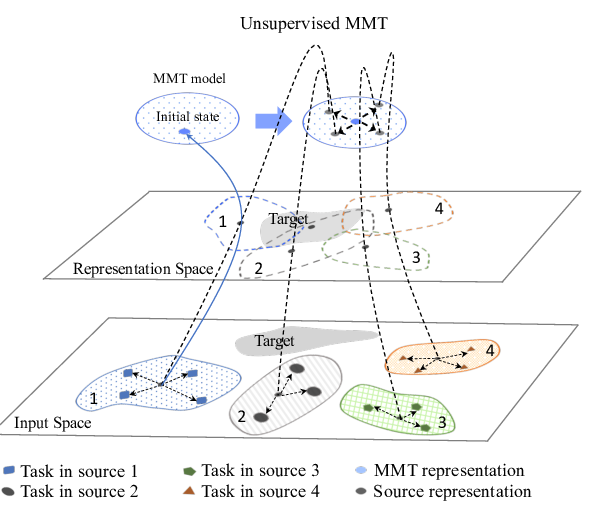
Multi-source Meta Transfer for Low Resource Multiple-Choice Question Answering
Ming Yan, Hao Zhang, Di Jin, Joey Tianyi Zhou,
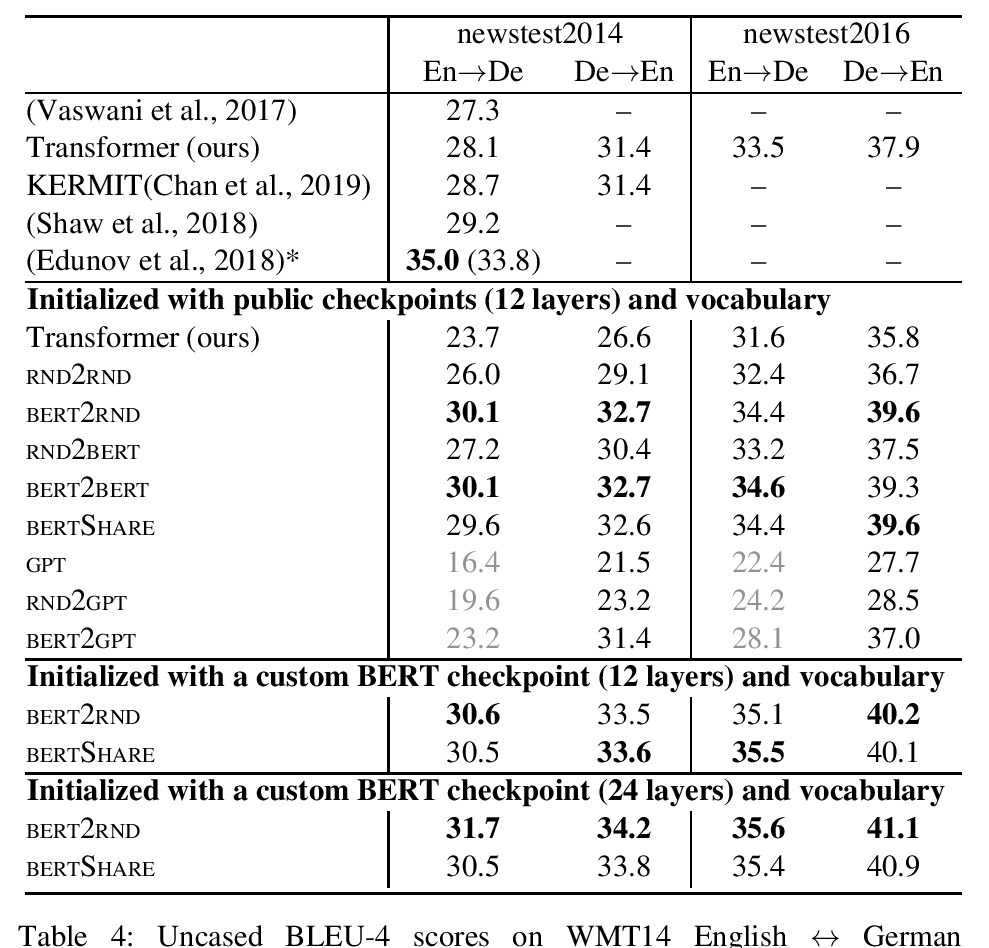
Leveraging Pre-trained Checkpoints for Sequence Generation Tasks
Sascha Rothe, Shashi Narayan and Aliaksei Severyn,
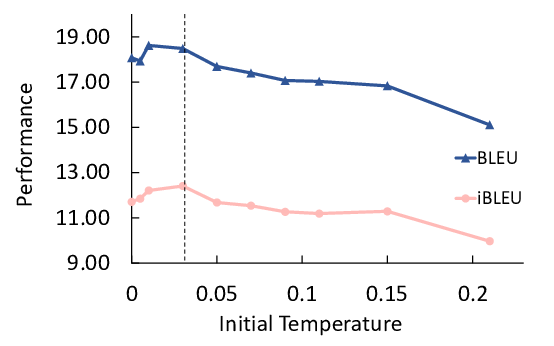
Unsupervised Paraphrasing by Simulated Annealing
Xianggen Liu, Lili Mou, Fandong Meng, Hao Zhou, Jie Zhou, Sen Song,
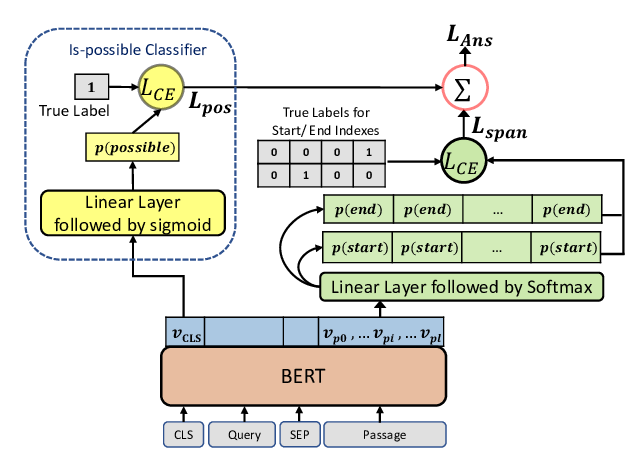
Span Selection Pre-training for Question Answering
Michael Glass, Alfio Gliozzo, Rishav Chakravarti, Anthony Ferritto, Lin Pan, G P Shrivatsa Bhargav, Dinesh Garg, Avi Sil,