Semi-supervised Contextual Historical Text Normalization
Peter Makarov, Simon Clematide
Phonology, Morphology and Word Segmentation Long Paper
Session 12B: Jul 8
(09:00-10:00 GMT)

Session 13B: Jul 8
(13:00-14:00 GMT)
Abstract:
Historical text normalization, the task of mapping historical word forms to their modern counterparts, has recently attracted a lot of interest (Bollmann, 2019; Tang et al., 2018; Lusetti et al., 2018; Bollmann et al., 2018;Robertson and Goldwater, 2018; Bollmannet al., 2017; Korchagina, 2017). Yet, virtually all approaches suffer from the two limitations: 1) They consider a fully supervised setup, often with impractically large manually normalized datasets; 2) Normalization happens on words in isolation. By utilizing a simple generative normalization model and obtaining powerful contextualization from the target-side language model, we train accurate models with unlabeled historical data. In realistic training scenarios, our approach often leads to reduction in manually normalized data at the same accuracy levels.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
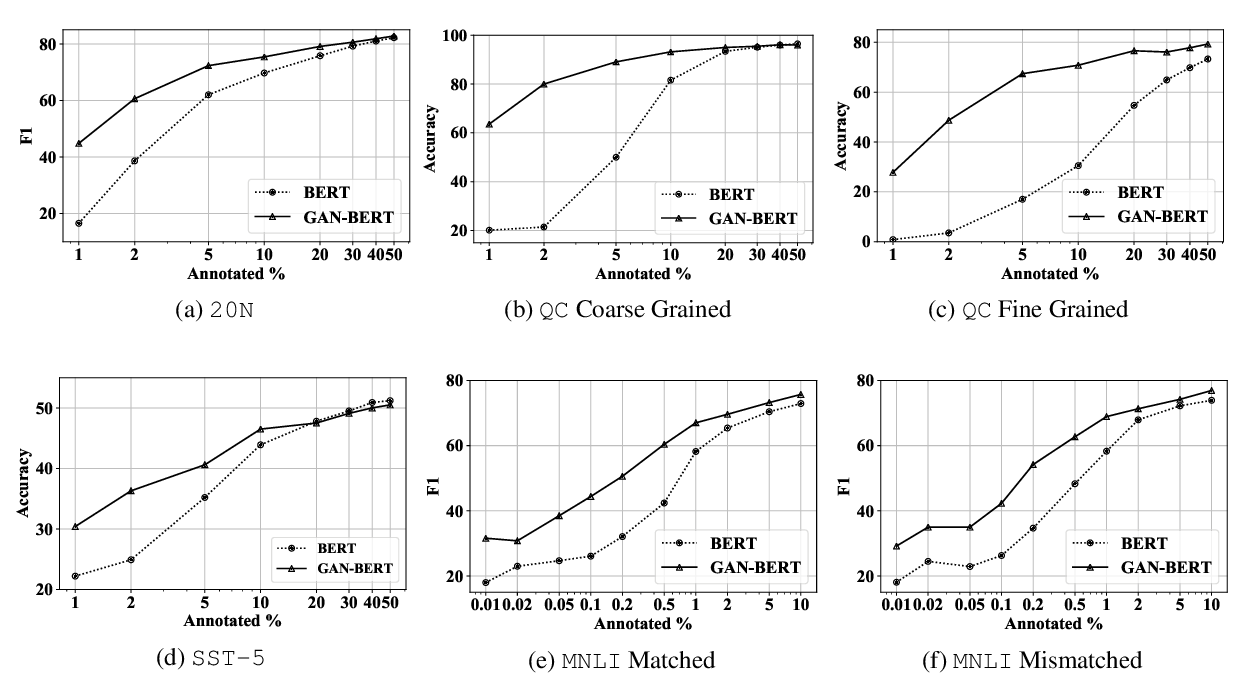
GAN-BERT: Generative Adversarial Learning for Robust Text Classification with a Bunch of Labeled Examples
Danilo Croce, Giuseppe Castellucci, Roberto Basili,
Modeling Word Formation in English–German Neural Machine Translation
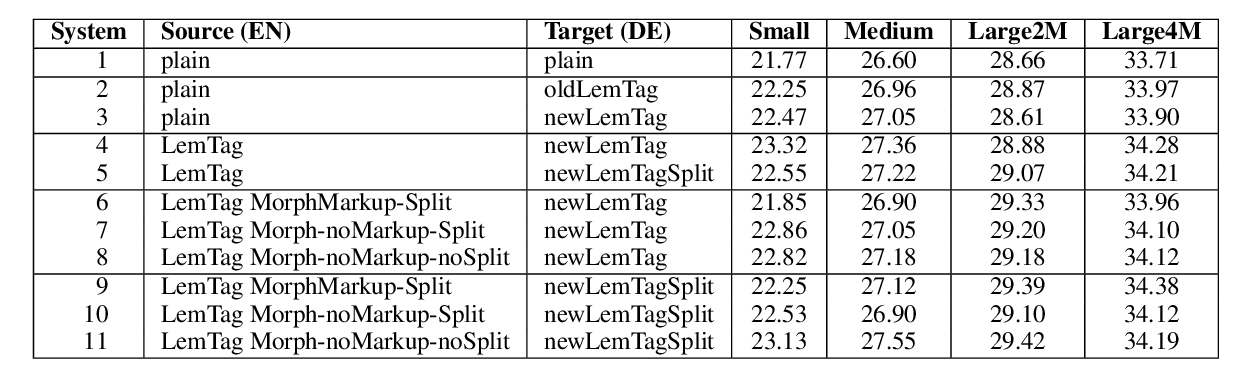
Marion Weller-Di Marco, Alexander Fraser,