A Call for More Rigor in Unsupervised Cross-lingual Learning
Mikel Artetxe, Sebastian Ruder, Dani Yogatama, Gorka Labaka, Eneko Agirre
Theme Long Paper
Session 12B: Jul 8
(09:00-10:00 GMT)

Session 13B: Jul 8
(13:00-14:00 GMT)
Abstract:
We review motivations, definition, approaches, and methodology for unsupervised cross-lingual learning and call for a more rigorous position in each of them. An existing rationale for such research is based on the lack of parallel data for many of the world's languages. However, we argue that a scenario without any parallel data and abundant monolingual data is unrealistic in practice. We also discuss different training signals that have been used in previous work, which depart from the pure unsupervised setting. We then describe common methodological issues in tuning and evaluation of unsupervised cross-lingual models and present best practices. Finally, we provide a unified outlook for different types of research in this area (i.e., cross-lingual word embeddings, deep multilingual pretraining, and unsupervised machine translation) and argue for comparable evaluation of these models.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Jointly Learning to Align and Summarize for Neural Cross-Lingual Summarization
Yue Cao, Hui Liu, Xiaojun Wan,
Unsupervised Multilingual Sentence Embeddings for Parallel Corpus Mining
Ivana Kvapilíková, Mikel Artetxe, Gorka Labaka, Eneko Agirre, Ondřej Bojar,
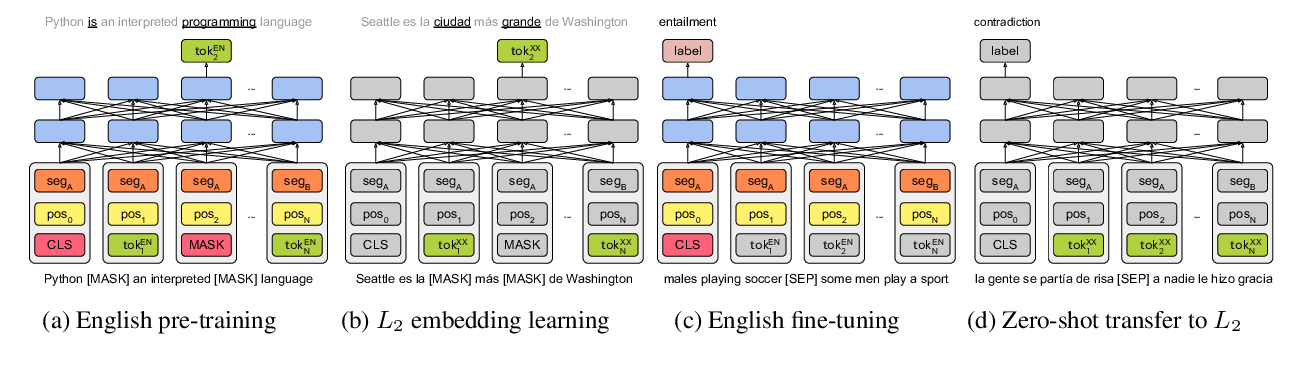
On the Cross-lingual Transferability of Monolingual Representations
Mikel Artetxe, Sebastian Ruder, Dani Yogatama,
Cross-Lingual Unsupervised Sentiment Classification with Multi-View Transfer Learning
Hongliang Fei, Ping Li,