Empower Entity Set Expansion via Language Model Probing
Yunyi Zhang, Jiaming Shen, Jingbo Shang, Jiawei Han
Information Retrieval and Text Mining Long Paper
Session 14A: Jul 8
(17:00-18:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
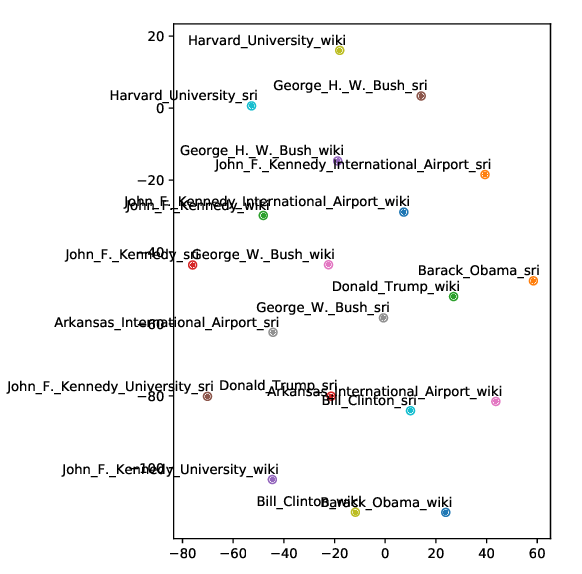
Entity set expansion, aiming at expanding a small seed entity set with new entities belonging to the same semantic class, is a critical task that benefits many downstream NLP and IR applications, such as question answering, query understanding, and taxonomy construction. Existing set expansion methods bootstrap the seed entity set by adaptively selecting context features and extracting new entities. A key challenge for entity set expansion is to avoid selecting ambiguous context features which will shift the class semantics and lead to accumulative errors in later iterations. In this study, we propose a novel iterative set expansion framework that leverages automatically generated class names to address the semantic drift issue. In each iteration, we select one positive and several negative class names by probing a pre-trained language model, and further score each candidate entity based on selected class names. Experiments on two datasets show that our framework generates high-quality class names and outperforms previous state-of-the-art methods significantly.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Relabel the Noise: Joint Extraction of Entities and Relations via Cooperative Multiagents
Daoyuan Chen, Yaliang Li, Kai Lei, Ying Shen,
Neighborhood Matching Network for Entity Alignment
Yuting Wu, Xiao Liu, Yansong Feng, Zheng Wang, Dongyan Zhao,
Improving Entity Linking through Semantic Reinforced Entity Embeddings
Feng Hou, Ruili Wang, Jun He, Yi Zhou,