TVQA+: Spatio-Temporal Grounding for Video Question Answering
Jie Lei, Licheng Yu, Tamara Berg, Mohit Bansal
Language Grounding to Vision, Robotics and Beyond Long Paper
Session 14A: Jul 8
(17:00-18:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
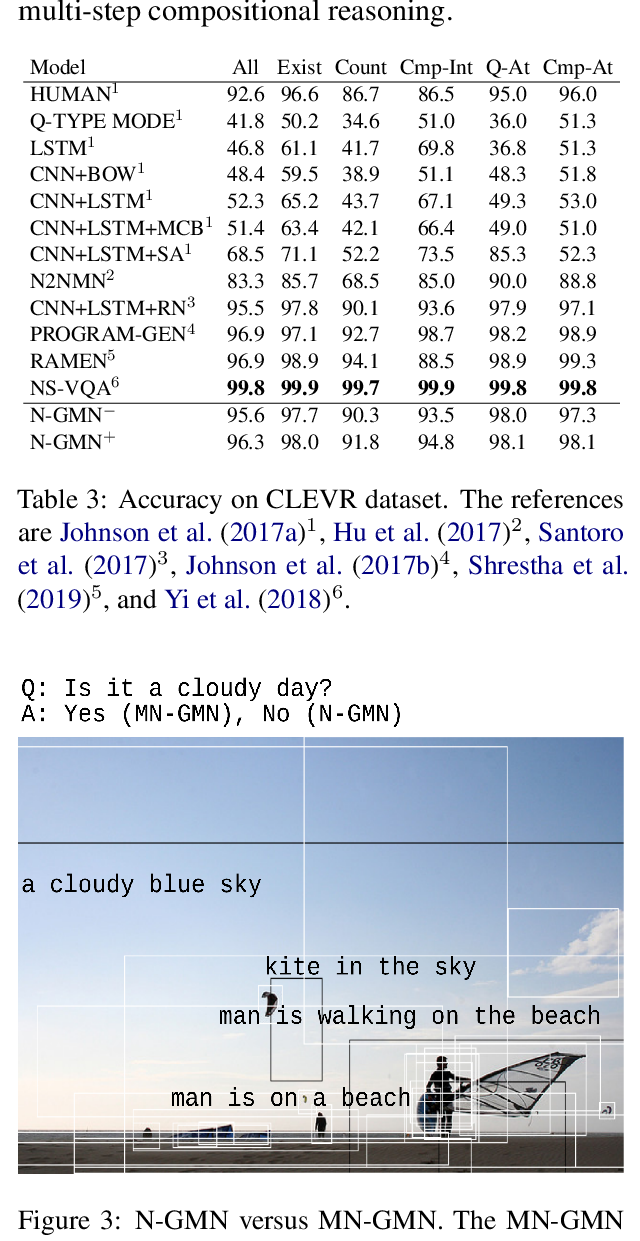
We present the task of Spatio-Temporal Video Question Answering, which requires intelligent systems to simultaneously retrieve relevant moments and detect referenced visual concepts (people and objects) to answer natural language questions about videos. We first augment the TVQA dataset with 310.8K bounding boxes, linking depicted objects to visual concepts in questions and answers. We name this augmented version as TVQA+. We then propose Spatio-Temporal Answerer with Grounded Evidence (STAGE), a unified framework that grounds evidence in both spatial and temporal domains to answer questions about videos. Comprehensive experiments and analyses demonstrate the effectiveness of our framework and how the rich annotations in our TVQA+ dataset can contribute to the question answering task. Moreover, by performing this joint task, our model is able to produce insightful and interpretable spatio-temporal attention visualizations.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Dense-Caption Matching and Frame-Selection Gating for Temporal Localization in VideoQA
Hyounghun Kim, Zineng Tang, Mohit Bansal,
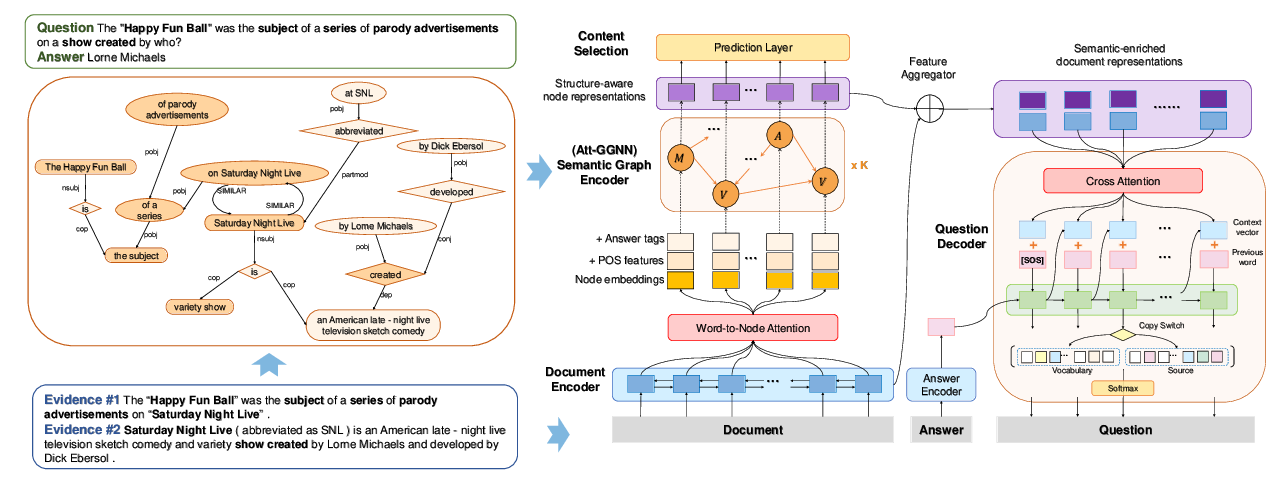
Semantic Graphs for Generating Deep Questions
Liangming Pan, Yuxi Xie, Yansong Feng, Tat-Seng Chua, Min-Yen Kan,
Harvesting and Refining Question-Answer Pairs for Unsupervised QA
Zhongli Li, Wenhui Wang, Li Dong, Furu Wei, Ke Xu,