A Multitask Learning Approach for Diacritic Restoration
Sawsan Alqahtani, Ajay Mishra, Mona Diab
Phonology, Morphology and Word Segmentation Long Paper
Session 14A: Jul 8
(17:00-18:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
In many languages like Arabic, diacritics are used to specify pronunciations as well as meanings. Such diacritics are often omitted in written text, increasing the number of possible pronunciations and meanings for a word. This results in a more ambiguous text making computational processing on such text more difficult. Diacritic restoration is the task of restoring missing diacritics in the written text. Most state-of-the-art diacritic restoration models are built on character level information which helps generalize the model to unseen data, but presumably lose useful information at the word level. Thus, to compensate for this loss, we investigate the use of multi-task learning to jointly optimize diacritic restoration with related NLP problems namely word segmentation, part-of-speech tagging, and syntactic diacritization. We use Arabic as a case study since it has sufficient data resources for tasks that we consider in our joint modeling. Our joint models significantly outperform the baselines and are comparable to the state-of-the-art models that are more complex relying on morphological analyzers and/or a lot more data (e.g. dialectal data).
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Joint Diacritization, Lemmatization, Normalization, and Fine-Grained Morphological Tagging
Nasser Zalmout, Nizar Habash,
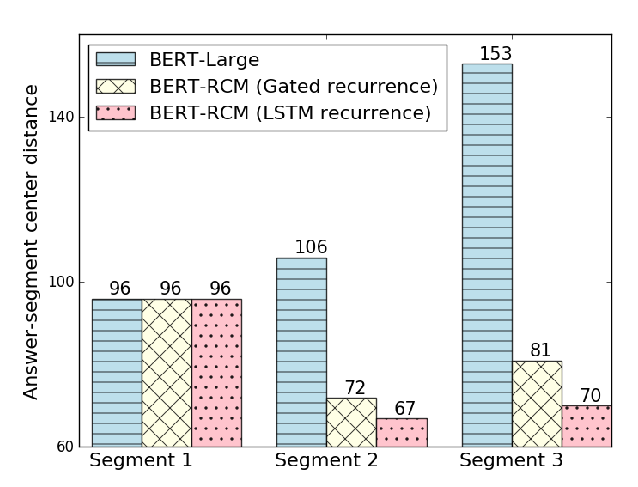
Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
Hongyu Gong, Yelong Shen, Dian Yu, Jianshu Chen, Dong Yu,
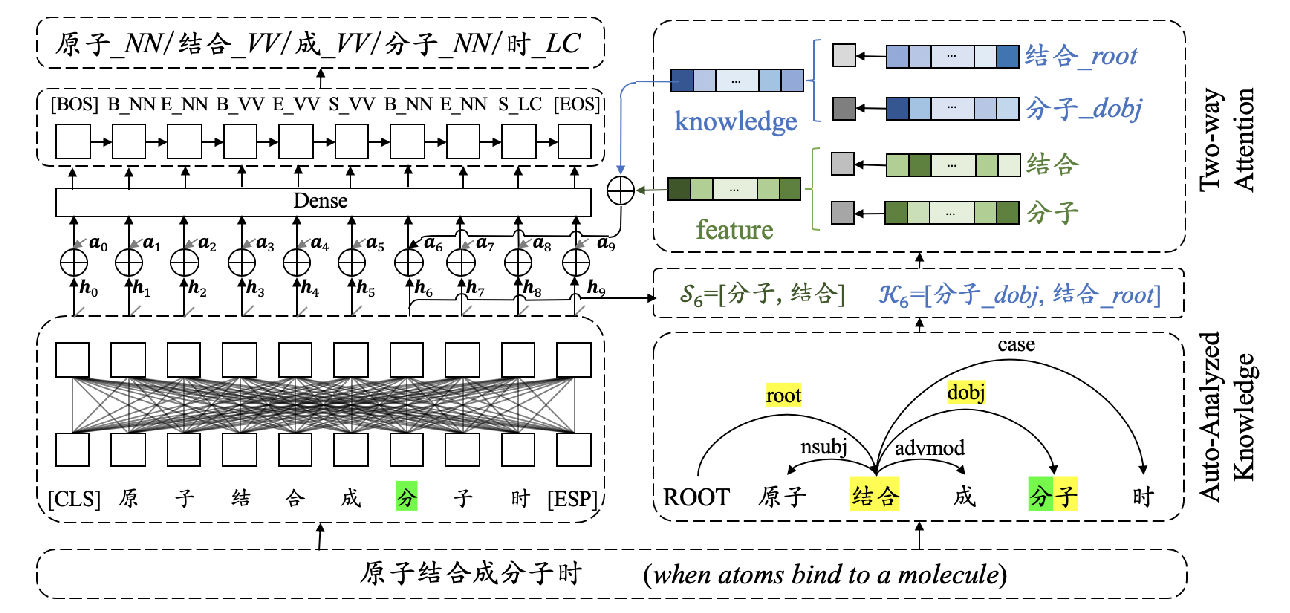
Joint Chinese Word Segmentation and Part-of-speech Tagging via Two-way Attentions of Auto-analyzed Knowledge
Yuanhe Tian, Yan Song, Xiang Ao, Fei Xia, Xiaojun Quan, Tong Zhang, Yonggang Wang,
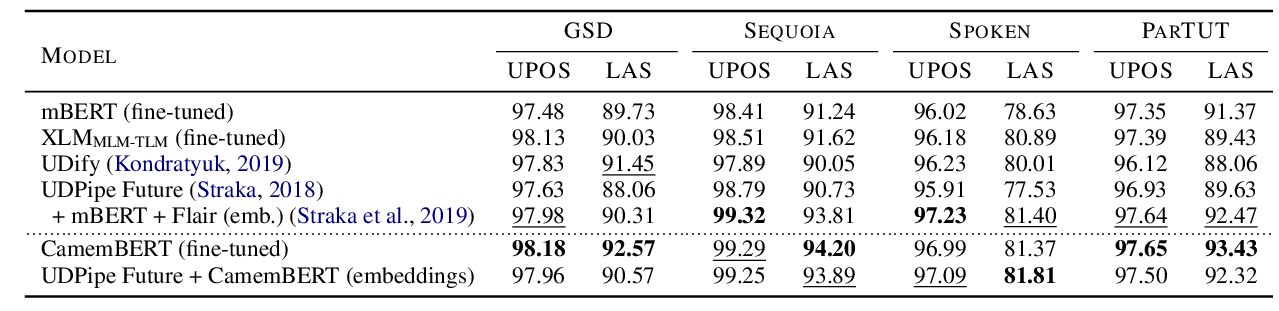
CamemBERT: a Tasty French Language Model
Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric de la Clergerie, Djamé Seddah, Benoît Sagot,