CamemBERT: a Tasty French Language Model
Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric de la Clergerie, Djamé Seddah, Benoît Sagot
Machine Learning for NLP Long Paper
Session 12B: Jul 8
(09:00-10:00 GMT)

Session 14B: Jul 8
(18:00-19:00 GMT)
Abstract:
Pretrained language models are now ubiquitous in Natural Language Processing. Despite their success, most available models have either been trained on English data or on the concatenation of data in multiple languages. This makes practical use of such models --in all languages except English-- very limited. In this paper, we investigate the feasibility of training monolingual Transformer-based language models for other languages, taking French as an example and evaluating our language models on part-of-speech tagging, dependency parsing, named entity recognition and natural language inference tasks. We show that the use of web crawled data is preferable to the use of Wikipedia data. More surprisingly, we show that a relatively small web crawled dataset (4GB) leads to results that are as good as those obtained using larger datasets (130+GB). Our best performing model CamemBERT reaches or improves the state of the art in all four downstream tasks.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
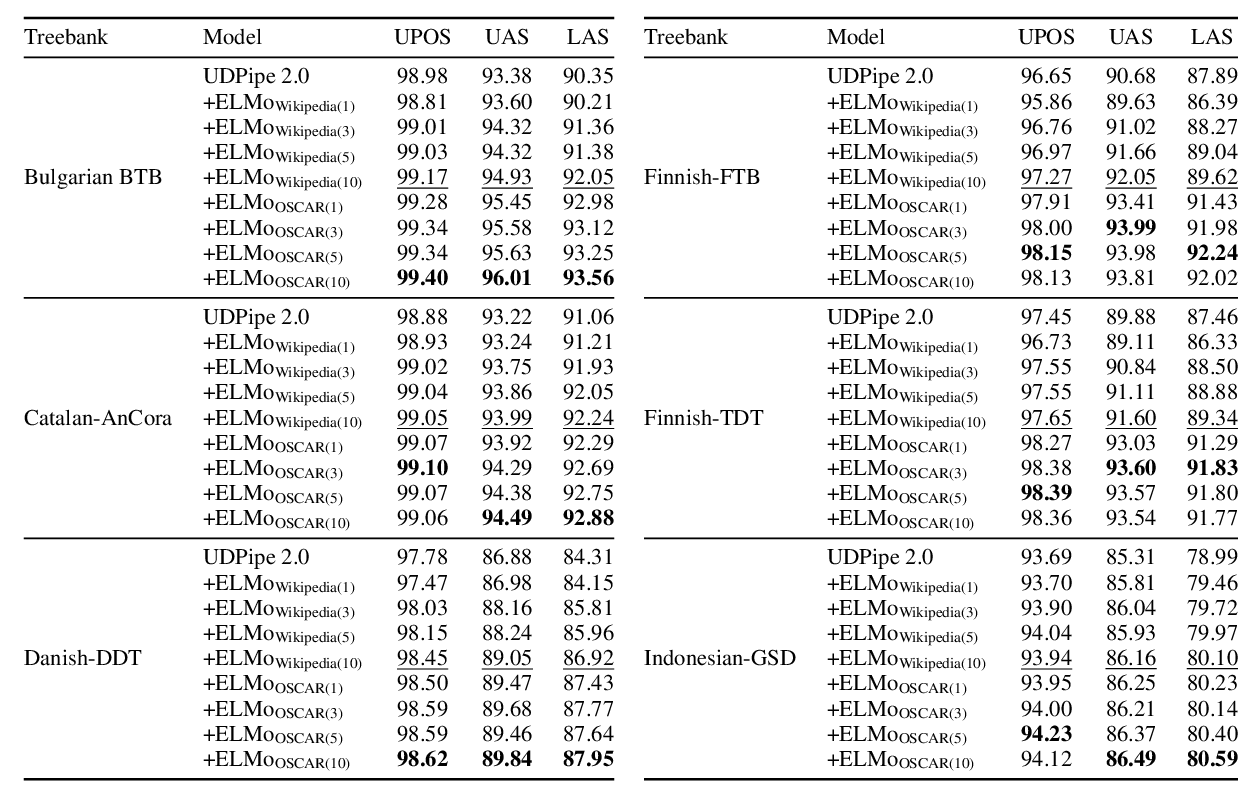
A Monolingual Approach to Contextualized Word Embeddings for Mid-Resource Languages
Pedro Javier Ortiz Suárez, Laurent Romary, Benoît Sagot,
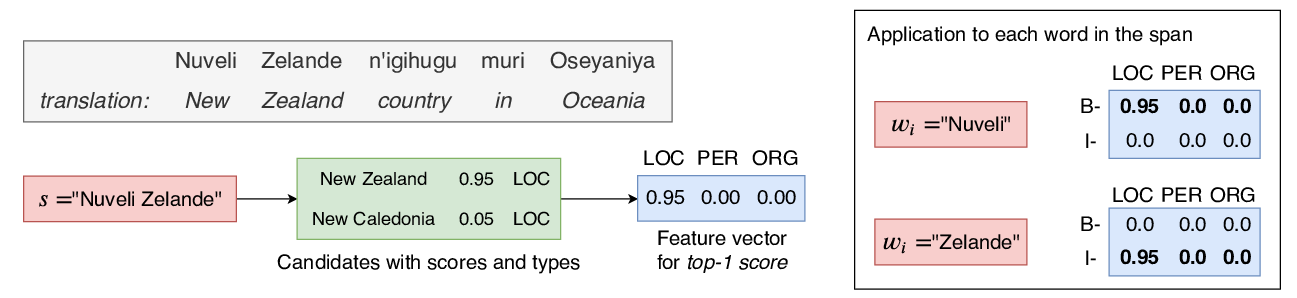
Soft Gazetteers for Low-Resource Named Entity Recognition
Shruti Rijhwani, Shuyan Zhou, Graham Neubig, Jaime Carbonell,
Transferring Monolingual Model to Low-Resource Language: The Case of Tigrinya
Abrhalei Frezghi Tela, Abraham Woubie Zewoudie, Ville Hautamäki,
