Joint Diacritization, Lemmatization, Normalization, and Fine-Grained Morphological Tagging
Nasser Zalmout, Nizar Habash
Phonology, Morphology and Word Segmentation Long Paper
Session 14A: Jul 8
(17:00-18:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
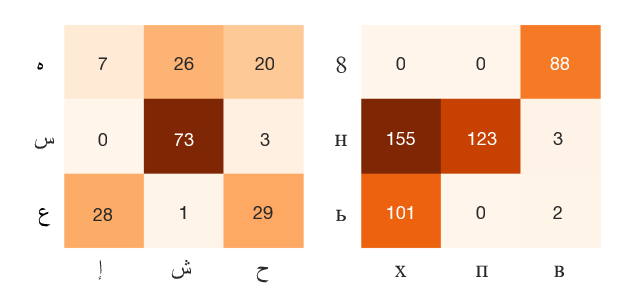
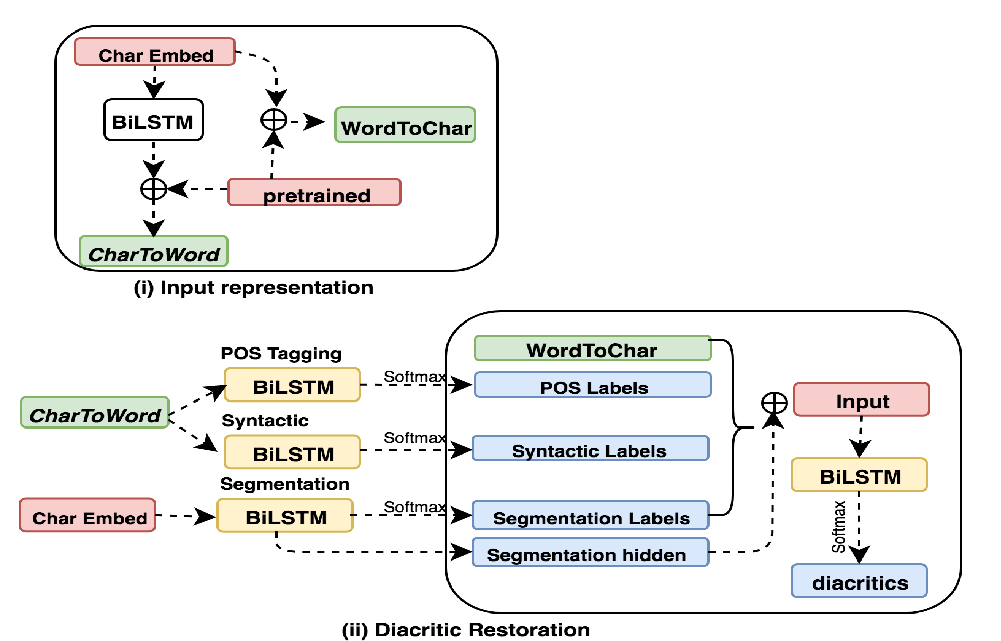
The written forms of Semitic languages are both highly ambiguous and morphologically rich: a word can have multiple interpretations and is one of many inflected forms of the same concept or lemma. This is further exacerbated for dialectal content, which is more prone to noise and lacks a standard orthography. The morphological features can be lexicalized, like lemmas and diacritized forms, or non-lexicalized, like gender, number, and part-of-speech tags, among others. Joint modeling of the lexicalized and non-lexicalized features can identify more intricate morphological patterns, which provide better context modeling, and further disambiguate ambiguous lexical choices. However, the different modeling granularity can make joint modeling more difficult. Our approach models the different features jointly, whether lexicalized (on the character-level), or non-lexicalized (on the word-level). We use Arabic as a test case, and achieve state-of-the-art results for Modern Standard Arabic with 20% relative error reduction, and Egyptian Arabic with 11% relative error reduction.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
AraDIC: Arabic Document Classification Using Image-Based Character Embeddings and Class-Balanced Loss
Mahmoud Daif, Shunsuke Kitada, Hitoshi Iyatomi,
Phonetic and Visual Priors for Decipherment of Informal Romanization
Maria Ryskina, Matthew R. Gormley, Taylor Berg-Kirkpatrick,